Cloudflare Gen 13 drops cache for core count
Cloudflare's Gen 13 launch proves a hard truth: 192-core density only beats legacy cache reliance when paired with a Rust-based rewrite. (Cloudflare's gen13 config)
The industry's obsession with massive 3D V-Cache is dead for high-throughput edge networks. Cloudflare proved this by migrating from AMD EPYC Genoa-X to 5th Gen Turin processors. The old Gen 12 fleet leaned on 12MB of L3 cache per core to stay fast. The new Turin 9965 chips deliberately slash that allocation to just 2MB per core to maximize thread count. This architectural gamble would have crippled the old FL1 request handling layer, which suffered dramatic L3 cache miss rates on high-density silicon. The fix wasn't better hardware; it was FL2, a modular architecture that kills cache dependency and lets throughput scale linearly with core count.
AMD uProf data exposed the fatal latency penalties of running legacy code on these modern CPUs. Rewriting core logic in Rust allowed Cloudflare to maintain strict SLAs while doubling core counts from 96 to 192. This transition ends the cache-heavy era for edge computing. Software modularity now dictates hardware viability more than raw silicon specs.
The Architectural Shift from Genoa-X 3D V-Cache to Turin High-Core Density
Genoa-X 3D V-Cache versus Turin High-Core Density Specifications
Gen 13 swaps 96-core Genoa-X processors for 192-core Turin units, halving cache availability per thread. We moved from 96C/192T configurations to 192C/384T layouts. This pivot trades cache capacity for raw compute density, forcing a re-evaluation of memory locality assumptions in edge request handling.
| Generation | Processor Model | Cores/Threads | L3 Cache Per Core |
|---|---|---|---|
| Gen 12 | AMD Genoa-X 9684X | 96C/192T | 12MB |
| Gen 13 | AMD Turin 9965 | 192C/384T | 2MB |
Per-core cache drops from 12MB to 2MB. That is a six-fold reduction in local storage for thread state. Despite this constraint, power efficiency improves; Turin consumes 32% fewer watts per core compared to Genoa-X. The limitation is severe. Workloads relying on large working sets face frequent DRAM fetches, spiking latency by over 50% at high utilization without software changes. Operators cannot simply migrate binaries. The FL2 rewrite becomes mandatory to decouple performance from cache locality. Throughput gains remain theoretical unless the application layer eliminates cache-dependent locking mechanisms.
Doubling the core count to 192 units enables up to 100% higher FL throughput despite reduced per-core cache. The AMD EPYC™ 5th Generation Turin 9965 processor delivers this scale using Zen 5 IPC improvements. Operators prioritizing raw throughput over cache locality find that core count expansion yields superior aggregate performance for stateless request handling. Each Gen 13 server integrates 768 GB of DDR5-6400 memory to sustain bandwidth demands across 384 threads without saturation. However, this architecture fails for workloads requiring deep cache locality. The 2MB per-core allocation cannot retain large working sets. The FL2 rewrite eliminates software-induced cache pressure, allowing hardware to reach theoretical maximums. Without such application-layer optimization, the latency spike from DRAM_fetches would negate throughput advantages. Pure core scaling remains ineffective if the software stack cannot parallelize efficiently across the expanded thread pool. This metric quantifies the ability to process more requests without expanding electrical infrastructure or increasing carbon output per unit of work. The uplift stems from Zen 5 architectural improvements. This efficiency enables sustainable scaling where previous generations would hit facility power ceilings. Reducing the carbon footprint per request becomes a direct function of architecture rather than just renewable sourcing.
L3 Cache Miss Cycles and DRAM Fetch Latency Mechanics
L3 cache hits resolve in roughly 50 cycles. Misses forcing DRAM access consume 350+ cycles. This seven-fold latency disparity defines the mechanical failure mode when per-core storage shrinks. Legacy stacks relying on local storage face immediate performance degradation as data evictions force frequent trips to main memory. The AMD uProf.
| Access Type | Cycle Cost | Dominant Factor |
|---|---|---|
| L3 Hit | ~50 cycles | Core-internal fabric |
| L3 Miss | 350+ cycles | DDR5 DRAM row activation |
High utilization exacerbates contention. Latency penalties scale non-linearly rather than linearly. Operators observing flat throughput despite added cores often find cache thrashing nullifying IPC improvements. The cost is measurable. Request paths previously serviced entirely within silicon now stall waiting for external memory controllers. Mitigation requires software re-architecture to reduce working set size per thread. Simply adding cores without adjusting data locality assumptions yields diminishing returns. The limitation is physical; no amount of tuning fixes a working set larger than the available 2MB slice. Ignoring this mechanical constraint turns a throughput upgrade into a latency regression.
AMD uProf Diagnostics for NGINX and LuaJIT Stack Bottlenecks
AMD uProf counters exposed L3 miss spikes driving memory fetch latency dominance in the legacy FL1 stack. Profiling data revealed that cache contention worsened linearly as CPU utilization climbed, invalidating static capacity models. The tool traced specific NGINX worker processes hitting DRAM boundaries where LuaJIT bytecode previously resided in local storage. Cloudflare collected these performance metrics to quantify the scaling failure, linking high core counts directly to request delays. Operators attempting to reduce request latency on high-core servers must first isolate these fabric bottlenecks before adding threads. Tuning DF Probe Filters yielded marginal gains because the root cause was capacity exhaustion, not prefetch inefficiency.
Unlocking Throughput Gains Through Rust Memory Safety and Modular Architecture
Rust Memory Safety and Modular Architecture in FL2
FL2 replaces 15 years of NGINX and LuaJIT code with a Rust-based stack built on Pingora and Oxy frameworks. Flexible allocation patterns that previously forced frequent trips to DRAM vanish under this new architecture. Strict module systems enforce memory safety at compile time, preventing runtime errors common in legacy scripting environments. The rewrite reduces dependency on massive cache sizes by optimizing memory access patterns directly within the binary. Defining PQOS reveals how hardware resource regulation complements this software overhaul. PQOS extensions enable fine-grained control over shared resources like cache slices and memory bandwidth across Core Complex Dies. Operators can dedicate entire CCDs to specific workloads, isolating critical request handling from noisy neighbors. This configuration yielded meaningful throughput gains where hardware prefetcher tuning failed. The AMD EPYC™ Turin 9965 processor benefits from this isolation because FL2 no longer competes for fragmented cache lines.
| Legacy Stack | FL2 Architecture | Result |
|---|---|---|
| Flexible LuaJIT allocation | Static Rust modules | Predictable latency |
| Cache-heavy design | Linear core scaling | 70% lower latency |
| Shared L3 contention | PQOS isolation | Stable SLAs |
Deployment cycles now require full binary swaps rather than script updates, increasing operational rigidity. Hot-reloading capabilities inherent to interpreted languages disappear completely. The Gen 13 design trades cache capacity for core count, making the leaner FL2 memory footprint mandatory rather than optional. Without this rewrite, the 2MB per-core cache limit would render the high-density silicon unusable for low-latency edge functions. Rewriting the request handling layer removes the cache contention bottleneck inherent in high-core-density hardware. Operators facing similar L3 cache reductions must evaluate whether legacy codebases can sustain throughput without unacceptable latency spikes. The performance-per-watt gains further validate the architectural shift, showing that efficiency scales alongside raw processing power. Such a drop allows network engineers to push CPU utilization higher while strictly maintaining service level agreements for edge functions. The 2x throughput. Legacy systems relying on large local caches will fail to scale linearly as core counts double in future generations.
FL1 Cache Contention Walls Versus FL2 Linear Core Scaling
FL1 hit a hard cache contention wall on Gen 13, forcing an unacceptable tradeoff between raw throughput and request latency. The legacy stack struggled as L3 cache per core dropped sharply, causing memory fetch operations to dominate processing time. FL2 uses a leaner memory access pattern that removes dependency on massive local storage, enabling linear scaling with core count. This architectural shift allows the system to achieve 2x the throughput of the previous generation while maintaining strict service level agreements. Maximizing core utilization on high-density silicon requires abandoning cache-locality assumptions entirely. Static capacity models fail when cache miss rates scale non-linearly with thread count.
Executing the Migration to Rust-Based Services with Cache Isolation Strategies
AMD PQOS and NUMA Affinity Mechanics for Cache Isolation
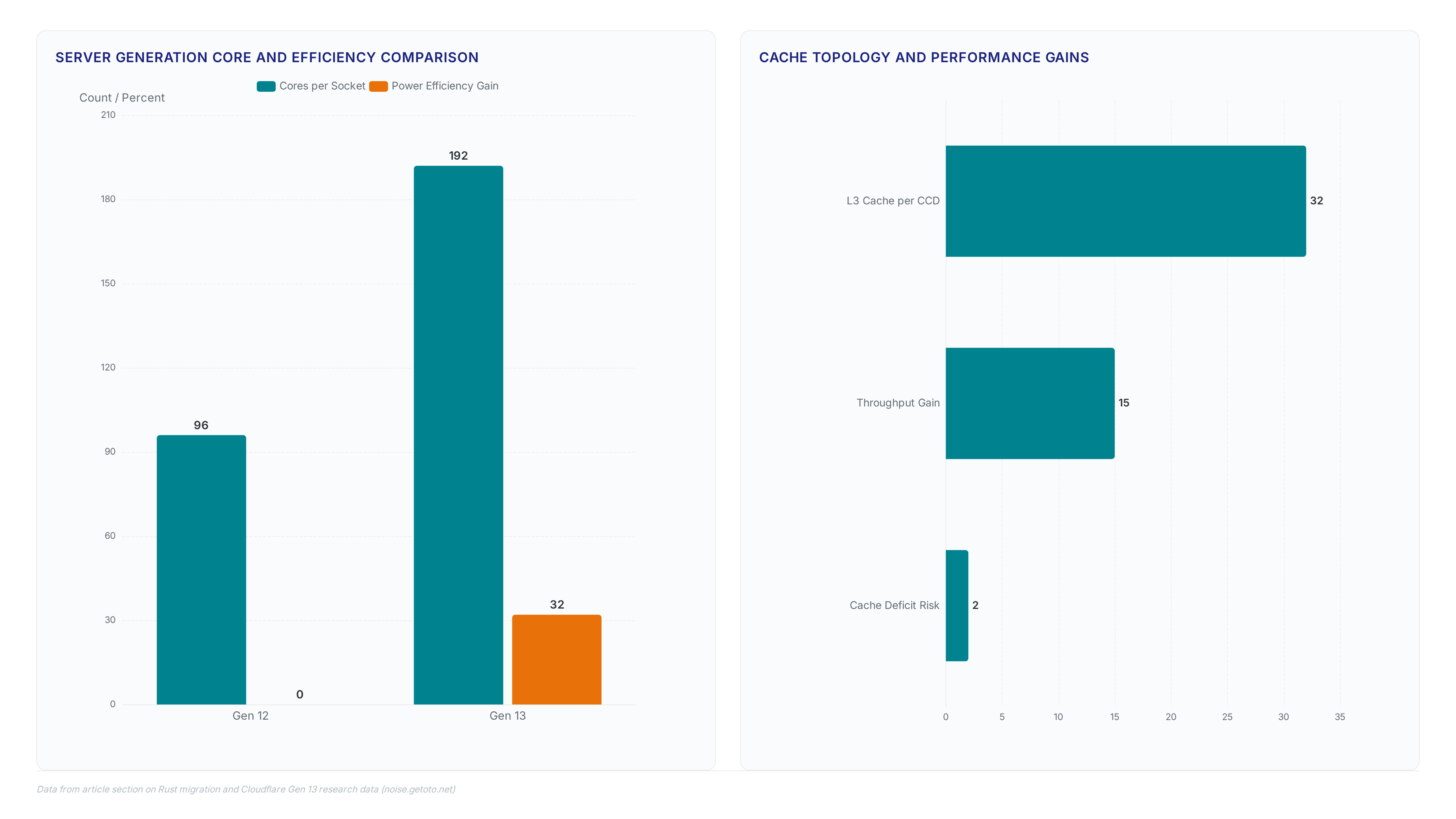
NUMA-aware core affinity across six of twelve CCDs delivered a >15% incremental throughput gain by isolating shared L3 resources. The Turin architecture splits the processor into one I/O Die and up to 12 Core Complex Dies, where each CCD shares a 32MB L3 cache slice among 16 cores. This topology forces operators to regulate access explicitly rather than relying on default hardware schedulers. AMD's Platform Quality of Service (PQOS) enables fine-grained control over these cache slices and memory bandwidth domains.
Implementing this isolation requires precise mapping of virtual CPUs to physical cores within set cache boundaries. A misconfigured affinity policy allows threads to drift across CCD borders, triggering costly inter-die fabric traversals. The architectural shift from cache-heavy designs necessitates this manual intervention to maintain performance stability. Without strict partitioning, high-density core counts exacerbate contention rather than alleviating. Operators must balance the complexity of manual pinning against the risk of uncontrolled cache thrashing. The power efficiency.
Migrating 15 years of NGINX and LuaJIT logic to the Rust-based FL2 architecture requires replacing flexible scripting with static memory safety guarantees found in the Pingora and Oxy frameworks:
- Audit legacy Lua hooks to identify stateful dependencies that rely on massive L3 cache locality for speed.
- Refactor request handlers into Rust modules that eliminate runtime interpretation overhead and reduce flexible allocation.
- Deploy isolated workers using CPU pinning strategies to prevent cache thrashing across the 12 Core Complex Dies.
- Validate throughput gains against baseline metrics before enabling full traffic shifts on high-density nodes.
This transition removes the latency penalty observed when legacy code paths force DRAM fetches due to cache misses. Operators must accept that code complexity increases initially as implicit runtime behaviors become explicit compile-time constraints. The shift enables linear scaling where previous architectures hit a contention wall at high utilization. Global edge networks spanning 310+ cities require such deterministic performance to complement hyperscaler backend storage without introducing variable lag. The resulting binary executes with predictable cycle counts regardless of core density. This approach sustains service levels even as cache per core shrinks drastically in newer silicon generations.
Hardware Tuning Pitfalls: DF Probe Filters and Worker Scaling Limits
Adjusting Data Fabric Probe Filters on Turin yielded only marginal gains, failing to offset the 2MB per-core cache deficit. Operators attempting to tune hardware prefetchers often discover that software architecture dictates performance more than silicon-level tweaks in high-density environments. The temptation to simply launch more FL1 workers creates a hidden resource cannibalization risk where throughput rises while competing production services starve. This scaling approach ignores the economic reality that inefficient resource usage drives up costs, similar to how CPU time utilized 13labs. Au/compare/ billing models penalize wasted cycles rather than raw request volume. Without strict isolation, aggressive worker scaling degrades overall system stability despite localized throughput bumps.
- Audit hardware filters to confirm DF Probe adjustments provide no measurable latency reduction before proceeding.
- Limit worker density to prevent memory bandwidth saturation across the 12 Core Complex Dies.
- Implement PQOS policies to reserve cache slices rather than relying on default scheduler behavior.
Neglecting these steps forces a trade-off where short-term throughput gains undermine long-term request limits compliance during peak traffic. InterLIR recommends prioritizing cache isolation over raw core utilization to maintain service level agreements.
About
Georgy Masterov, a Customer Support Specialist at InterLIR and Computational Business Analytics student, bridges the gap between infrastructure evolution and resource management. While his daily work focuses on optimizing IPv4 availability and ensuring network security, his academic background in IT and finance provides a unique lens for analyzing hardware scalability. The transition to AMD EPYC™ 5th Gen Turin processors directly impacts the efficiency of global network services, a core concern for InterLIR as it enables critical IP redistribution. Masterov's experience with data-driven decision-making allows him to articulate how architectural shifts, like Cloudflare's move to FL2, resolve latency bottlenecks without relying on massive cache sizes. By connecting high-performance computing trends to practical network resource allocation, he highlights how next-generation silicon supports the transparent, efficient infrastructure that companies like InterLIR depend on to solve global connectivity challenges.
Conclusion
Turin's architectural efficiency creates a paradox where power savings mask severe contention risks at scale. As core density doubles, the reduced cache footprint forces frequent DRAM fetches that spike latency by over 50% when software lacks explicit isolation. This mechanical constraint means raw throughput gains vanish without strict CPU pinning, leaving clusters vulnerable to unpredictable lag during peak IoT or streaming surges. The operational cost shifts from electricity bills to complexity in workload orchestration, demanding that teams treat cache slices as finite, protected resources rather than shared pools.
Organizations must mandate cache-aware scheduling policies before deploying Gen 13 silicon into production environments by Q4 2027. Relying on default schedulers guarantees failure to reach the theoretical 62% throughput ceiling, regardless of hardware investment. The window for reactive tuning closes once traffic patterns stabilize on the new architecture. Start by auditing your current worker-to-core mapping ratios this week to identify processes exceeding the 2MB per-core safety threshold. This immediate inventory reveals hidden bottlenecks that hardware prefetchers cannot solve. Prioritizing deterministic performance over maximum core utilization ensures service levels remain stable as edge computing markets expand toward $19.1 billion.
Frequently Asked Questions
Legacy code fails because per-core cache drops drastically from 12MB to 2MB. This reduction forces frequent DRAM fetches, spiking latency by over 50% at high utilization without specific software changes to handle memory locality.
The Rust-based FL2 rewrite enables realizing 100% higher FL throughput gains with Turin 9965 Pro. This software change eliminates cache-dependent locking, allowing the system to scale linearly across the expanded thread pool effectively.
Each Gen 13 server integrates 768 GB of DDR5-6400 memory to sustain bandwidth. This large capacity is essential to feed all 384 threads without saturation when per-core cache is limited to just 2MB.
Without CPU pinning, the theoretical 62% throughput ceiling remains unreachable on high-density chips. Operators must isolate cache usage to prevent contention, ensuring the 192-core architecture delivers its promised aggregate performance benefits.
Turin consumes 32% fewer watts per core compared to Genoa-X while doubling core counts. This efficiency allows sustainable scaling where previous generations would hit facility power ceilings during intense edge computing workloads.
