eBPF offloading limits: Why 55K requests stall
Saturating a 400 Gbit link with standard TCP demands nearly all 64 cores, whereas DPDK achieves peak throughput on just a few. This disparity isn't about security fears; it's about architecture. Current kernel runtime designs choke on complex user-space logic. Giants like Cloudflare and Netflix run eBPF successfully for stateless functions, but the technology hits a wall in web servers and databases. These environments demand blocking operations and complex state management that the sandbox simply cannot support. (Cloudflare's kernel bypass)
Partial offloading often makes things worse. Memory copying mechanics inside the kernel eat the gains you expect from in-kernel processing. We need to look hard at the trade-offs between XDP and SK_SKB hooks. Pick the wrong one for latency-sensitive workloads, and you get jitter no amount of code tuning can fix. The verifier and compiler toolchain impose hard constraints that theoretical diagrams ignore.
By 2027, autonomous AI agents will manage connectivity without human intervention. If we don't fix these runtime limitations, self-optimizing systems will remain shackled to inefficient context switches. Data from Politecnico di Milano confirms this. The next generation of networked applications needs concrete metrics, not hype. You need to know if eBPF offloading is a solution or a trap for your specific infrastructure.
The Role of eBPF Offloading in Modern Network Infrastructure
eBPF Offloading Architecture and Verifier Constraints
eBPF offloading runs network logic inside the kernel, but verifier constraints kill complex loops and blocking I/O. The data path model works for simple network functions but fails for general applications. Unlike kernel-bypass libraries like OpenOnload that use LD_PRELOAD interposition, eBPF offers sandboxed execution without modifying source code or loading modules. Safety guarantees prevent unrestricted memory access that could cause kernel panics, yet these same rules forbid file I/O operations.
Developers face significant development overhead because the compiler toolchain cannot optimize certain instruction sequences as efficiently as native userspace code. The strict verifier limits program complexity. You gain safety; you lose flexibility.
eBPF Copy Latency Versus Kernel Module Performance
Memory copy overhead in eBPF reaches 340 ns for 1KB blocks. That is a tenfold penalty against native kernel modules. Traditional kernel modules hit a 32 ns baseline by accessing memory directly. EBPF helpers enforce strict boundary checks on every operation. This latency gap exists because the JIT compiler emits less efficient instructions to satisfy safety guarantees within the sandboxed runtime.
Kernel-bypass stacks like stock SPDK complete read I/Os in as few as 294 cycles. They bypass the kernel entirely to avoid these copy penalties. Operators evaluating deployment complexity must weigh this copy cost against the operational burden of loading unsigned kernel modules. The performance divergence forces a strategic choice: full offloading for raw speed or partial offloading for maintainability.
| Metric | eBPF Runtime | Kernel Module | Kernel-Bypass (SPDK) |
|---|---|---|---|
| Copy Time (1KB) | 340 ns | 32 ns | N/A (Zero-copy) |
| Execution Context | Sandboxed Kernel | Native Kernel | Userspace |
| Safety Model | Verifier Enforced | Manual Audit | Application Logic |
| I/O Completion | High Overhead | Low Overhead | 294 Cycles |
Full offloading maximizes throughput but sacrifices the ability to perform blocking I/O or complex stateful logic inside the kernel. Partial offloading retains flexibility for control-plane tasks while accelerating data-plane flows, yet it introduces context-switching latency for cache misses. Applications performing frequent large memory copies will suffer measurable degradation compared to native code paths. Network architects should reserve eBPF for filtering and monitoring tasks where copy volume remains low relative to packet count. High-throughput storage or database workloads require hardware offload capability or userspace bypass to meet strict latency service-level objectives.
Inside eBPF Runtime Overhead and Memory Copying Mechanics
JIT Compiler Instruction Efficiency Limits in eBPF Runtime
Mechanics: Partial Offloading Mechanics in BMC Key-Value Store Accelerator
BMC accelerates key-value stores by caching hot data in-kernel while forcing cold requests through userspace logic. This partial offloading design mitigates verifier constraints that forbid complex loops and blocking I/O inside the sandboxed runtime. Operators split the data path so that frequent lookups avoid costly context switches while rare misses trigger full-stack processing. The strategy yields a 2.5x throughput improvement yet increases latency for the minority of flows requiring userspace handling.
Accelerating the majority inadvertently degrades performance for edge cases needing complex application logic. Memory operations inside the eBPF VM suffer from instruction inefficiency compared to native kernel code execution paths. Copying data blocks takes notably longer because the JIT compiler emits verbose sequences to enforce safety boundaries. Developers face added development overhead when tuning split logic between kernel helpers and userspace daemons. The architecture prevents unrestricted memory access that could cause kernel panics but restricts available CPU instructions for data manipulation. Selecting the correct hook determines whether packets bypass the network stack entirely or traverse socket queues before processing. System designers must weigh these factors carefully.
| Component | Location | Constraint |
|---|---|---|
| Hot Cache | Kernel | No blocking I/O |
| Cold Logic | Userspace | Full instruction set |
| Verifier | Runtime | Blocks infinite loops |
This approach balances safety guarantees with performance needs for general networked applications running on standard Linux distributions.
SPDK Read I/O Cycles Versus eBPF Invocation Latency
A minimal custom SPDK variant executes read operations in just 183 cycles, dwarfing standard kernel paths. Stock configurations require 294 cycles for similar tasks, exposing the heavy tax of multiple abstraction layers. eBPF invocation latency introduces a different bottleneck entirely, often consuming microseconds before logic even begins. Context object preparation and mandatory safety checks within the runtime environment drive this delay.
Operators troubleshooting performance degradation in userspace frequently overlook how hook selection dictates this initial penalty. Attaching to socket layers incurs far higher overhead than driver-level hooks due to queue interactions. The following table contrasts cycle counts and latency sources for common data path strategies:
| Strategy | Metric | Primary Overhead Source |
|---|---|---|
| Custom SPDK | 183 cycles | User polling loop |
| Stock SPDK | 294 cycles | Library abstraction |
| eBPF XDP | ~38 ns | Context switch |
| eBPF Socket | >1000 ns | Queue management |
Kernel-bypass stacks excel at raw throughput by eliminating system calls entirely. Conversely, eBPF programs prioritize safety and observability over raw speed in containerized environments. Gaining non-intrusive monitoring capabilities sacrifices the deterministic low-latency required for storage I/O. Deployments needing sub-microsecond response times cannot rely on standard eBPF paths for data movement. Storage systems demand predictable timing that current sandboxing models struggle to provide without significant tuning.
XDP versus SK_SKB Hook Selection for Latency Sensitivity
XDP and SK_SKB Hook Latency Profiles Set
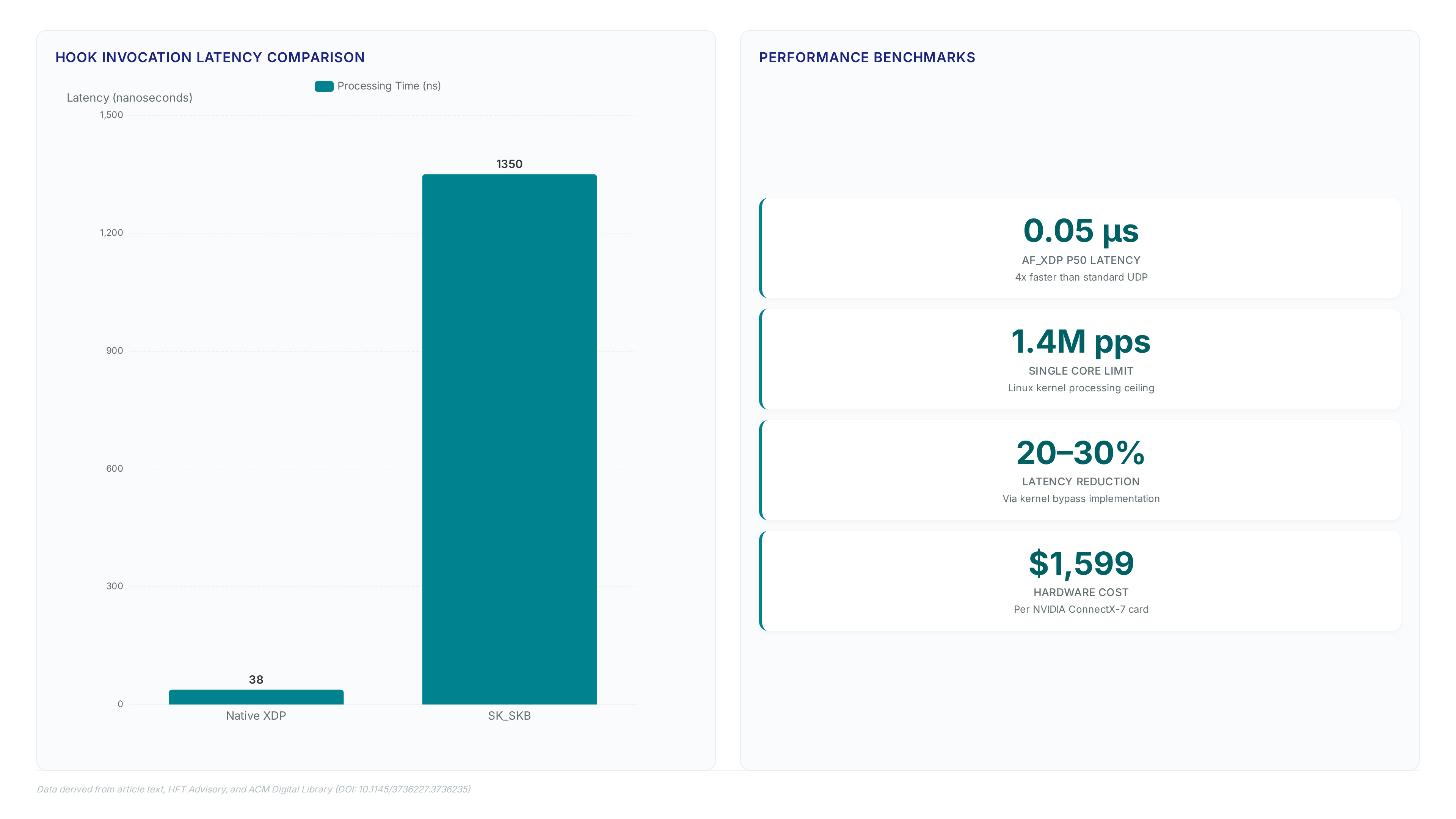
XDP invocation consumes 38 ns while SK_SKB requires over 1,350 ns due to socket queue interactions. This disparity defines the fundamental performance gap between driver-level and transport-layer attachment points. Operators selecting hooks must recognize that SK_SKB traverses the full network stack, inheriting context-switching penalties absent in Native XDP modes. The cost of waiting for in-order delivery via socket layers exceeds a microsecond before application logic even executes.
| Dimension | XDP Hook | SK_SKB Hook |
|---|---|---|
| Invocation Latency | 38 ns | >1,350 ns |
| Stack Traversal | Pre-network stack | Post-network stack |
| Packet Context | Individual frames | Socket buffers |
Choosing SK_SKB sacrifices raw speed for transport protocol services like reliable delivery, a trade-off unacceptable for microsecond-sensitive workloads. High-frequency trading firms investing millions in kernel-bypass stacks validate that avoiding these socket queues remains necessary for latency reduction. Generic XDP offers compatibility but lacks the direct hardware access of Native modes, creating a secondary variance in processing time. Hook selection dictates the baseline floor; no amount of eBPF code optimization can recover the time lost entering the socket layer.
Tick-to-trade velocity demands the XDP hook because SK_SKB invocation latency exceeds 1,350 ns, destroying arbitrage windows. High-frequency trading firms investing $1M–$2M in kernel-bypass stacks validate this architectural mandate through measured performance gains. Operators achieve a 20–30% reduction in total latency by bypassing the network stack entirely at the driver level. Standard UDP processing cannot compete when AF_XDP implementations deliver packet speeds four times quicker under load. The cost of NVIDIA ConnectX-7 hardware, priced near $1,599 per unit, remains negligible against the revenue impact of microsecond delays.
Selecting SK_SKB forfeits the primary advantage of eBPF acceleration by retaining full network stack traversal overhead. Financial applications requiring in-order delivery face a hard ceiling where transport protocol services introduce unacceptable jitter. Partial offloading strategies fail here because the 38 ns entry point is the only viable path for time-sensitive market data. The limitation remains strict: applications needing complex TCP state tracking must accept the microsecond tax or move logic to userspace bypass stacks.
AF_XDP achieves 0.05 µs P50 latency while saturating a 400 Gbit link demands nearly all 64 cores with standard TCP. This disparity exposes a hard ceiling where protocol abstraction consumes compute capacity that raw packet processing avoids entirely. Standard stacks incur massive overhead from context switches and memory copies inherent to the Linux kernel networking path. Operators attempting to scale traditional sockets on high-speed links face diminishing returns as core counts max out before line rate.
| Metric | AF_XDP Bypass | Standard TCP Stack |
|---|---|---|
| P50 Latency | 0.05 µs | Microseconds+ |
| Core Efficiency | Few cores | ~64 cores |
| Processing Layer | Driver level | Full system stack |
The architectural penalty for maintaining ordered delivery via sockets outweighs benefits for latency-sensitive workloads. Native XDP modes eliminate the socket buffer queue entirely, whereas SK_SKB hooks inherit full-stack traversal costs. Choosing the wrong attachment point forces the CPU to manage state machines that application logic could handle more efficiently in userspace. Gain wire-speed efficiency by sacrificing built-in transport guarantees.
Implementing High-Performance eBPF Patterns for Network Acceleration
Defining Partial Offloading Mechanics for In-Kernel Caching

Partial offloading isolates hot data paths in the kernel to bypass verifier constraints while retaining complex logic in userspace. The BMC accelerator model proved this split architecture yields a 2.5x throughput improvement by caching frequently accessed keys directly inside the kernel memory. Operators must recognize that only a fraction of traffic typically requires full userspace processing, allowing the majority of requests to skip expensive context switches.
However, shifting logic creates a problem: userspace latency increases for cache misses due to the overhead of crossing the kernel boundary. Managing state consistency between the isolated kernel cache and the primary application process adds complexity (Damonyuan.com/tech/260203-). Generic hook selection further complicates deployment, as Generic XDP offers compatibility but lacks the performance of driver-loaded modes necessary for high-frequency caching. Hardware capabilities also dictate viability, since offloaded XDP moves processing to the NIC but removes the flexibility needed for flexible cache updates. Offloading without measuring the cache hit ratio often degrades overall system performance rather than improving.
Implementing Priority Scheduling to Mitigate SK_SKB Invocation Overhead
SK_SKB hook invocation consumes 1,350 ns per packet, destroying latency budgets for transport-aware applications requiring in-order delivery. Operators must decouple high-priority traffic from standard socket queues to prevent head-of-line blocking within the kernel networking stack. The Linux kernel processes over a million packets per second on a single queue, yet SK_SKB overhead creates a bottleneck before application logic executes. Deploying priority scheduling reorders context preparation, allowing critical frames to bypass standard queue contention during high-load scenarios.
| Strategy | Latency Impact | Complexity |
|---|---|---|
| Standard SK_SKB | >1 µs base | Low |
| Priority Scheduled | Reduced variance | High |
| Full XDP Offload | 38 ns floor | Medium |
Bytedance simplified their stack using netkit deployments across dozens of clusters, proving that architectural changes reduce maintenance overhead without sacrificing observability. However, priority scheduling increases verifier constraints because the eBPF runtime rejects complex branching logic required for flexible reordering. This limitation forces developers to choose between strict priority enforcement and program feasibility within the current eBPF architecture. Research indicates cloud-native environments benefit from hybrid approaches where only specific control packets trigger high-overhead hooks. Tighter integration reduces overhead but demands significant changes to the underlying runtime behavior. Operators ignoring this balance face unpredictable latency spikes when background traffic saturates the default socket buffer processing path.
Risk Assessment: When eBPF JIT Inefficiency Outweighs Web Server Acceleration Benefits
Copying 1KB of data consumes 340 ns in eBPF versus 32 ns in native kernel modules, creating a 10x penalty that invalidates web server offloading strategies. This JIT inefficiency stems from the compiler emitting suboptimal instructions, forcing operators to accept higher latency for memory-intensive workloads compared to userspace execution. Hardware offload capability pushes packet processing costs from the CPU to the NIC, maximizing throughput in data centers where generic kernel paths fail under load (Hardware Offload Capability). However, application suitability dictates that eBPF remains uniquely suited for non-intrusive monitoring rather than high-throughput storage or web serving where kernel bypass is difficult (Application Suitability).
| Execution Path | Memory Copy Cost | Best Use Case |
|---|---|---|
| Native Userspace | Low (32 ns) | Web servers, databases |
| eBPF Runtime | High (340 ns) | Filters, monitors |
| Kernel Module | Low (32 ns) | Custom accelerators |
Operators must calculate whether their traffic profile justifies the runtime limitations before deploying in-kernel logic for general applications. InterLIR recommends avoiding eBPF for web acceleration when memory copy operations exceed simple packet filtering requirements.
About
Vladislava Shadrina serves as a Customer Account Manager at InterLIR, a specialized IPv4 address marketplace based in Berlin. While her background includes architecture, her daily work focuses on client relations and managing critical IP resources for global networks. This role provides unique insight into the infrastructure challenges discussed in articles about eBPF programs, as efficient network performance directly impacts the reliability of IP address distribution. At InterLIR, ensuring security through clean BGP and optimized routing is paramount; understanding low-level kernel technologies like eBPF helps explain how modern systems achieve the efficiency and transparency the company values. By bridging customer needs with technical realities, Shadrina connects the theoretical performance gains of eBPF network applications to practical outcomes in network availability. Her experience managing high-stakes IP leases highlights why optimizing data-plane performance is necessary for maintaining the integrity of today's internet infrastructure.
Conclusion
Scaling eBPF beyond monitoring reveals a hard ceiling where JIT compilation overhead destroys margins for memory-intensive workloads. High-frequency trading justifies million-dollar hardware investments to shave microseconds, but general web services face a 10x latency penalty during data copying that no amount of NIC offloading can mask. The operational cost shifts from simple deployment to continuous profiling, as background traffic saturation triggers unpredictable spikes that bypass traditional queue management. In-kernel logic is not a universal accelerator; it fractures under the weight of complex state management compared to native userspace execution.
Deploy eBPF strictly for stateless filtering and telemetry by Q3 2026, but mandate userspace execution for any workload requiring heavy memory manipulation or persistent connection state. Do not attempt to force kernel-resident logic onto storage layers or flexible web servers where the 340 ns copy cost erodes your SLA guarantees immediately. Start by auditing your current packet processing pipeline this week to isolate every memory copy operation exceeding 500 bytes, then map these specific paths to native userspace handlers before your next traffic peak. This targeted segregation ensures you capture observability benefits without surrendering throughput to compiler inefficiencies.
Frequently Asked Questions
Offloading hot data to the kernel creates resource contention that delays remaining userspace traffic. This architectural split forces cold requests to traverse the full network stack while saturating a 400 Gbit link.
The BMC accelerator keeps the majority of hot data requests inside the kernel to avoid standard overhead. Specifically, 55K requests stay in-kernel while only 5K cold requests per second enter userspace.
Native XDP hooks operate before the network stack to strictly minimize context switches and data copying. Selecting socket-level hooks instead introduces unpredictable jitter that degrades performance on high-speed 400 Gbit links.
Strict verifier constraints block complex loops and forbid blocking operations like file I/O or waiting states. These absolute limitations force developers to split logic, preventing eBPF from managing intricate state machines alone.
Standard TCP demands nearly all 64 cores to saturate a link, whereas DPDK achieves peak throughput on just a few. This disparity proves current kernel runtime architectures struggle with complex user-space logic overhead.
