Private CloudFront origins cut public IP risk now
You can eliminate public IPs for CloudFront origins with zero additional cost beyond standard rates. By 2026, the industry shift toward zero-trust Architecture will treat VPC Origins not as a luxury, but as the mandatory mechanism to seal the gap between public edge and private backends. This guide navigates the architectural trade-offs between centralized networking accounts and distributed resource models. We dissect the internal mechanics of cross-account VPC sharing, detailing how to route traffic securely without relying on expensive NAT Gateways or bastion hosts. The focus remains on locking down Application Load Balancers and EC2 instances behind security groups that admit only CloudFront traffic.
We provide a concrete roadmap for executing a zero-downtime migration, ensuring your transition from public to private origins does not alter live user sessions. By using AWS Resource Access Manager, organizations enforce strict access controls at the distribution layer while drastically reducing the surface area for DDoS attacks. This is no longer about theoretical security postures; it is about using native AWS capabilities to render your origin infrastructure invisible to the public internet.
The Role of Private VPC Origins in Modern Cloud Security Architecture
CloudFront VPC Origins and Private Network Architecture
CloudFront VPC Origins establish a private link connecting distributions directly to internal Application Load Balancers (ALBs) or Network Load Balancers (NLBs) without public internet exposure. General availability arrived on November 20, 2024, replacing legacy public origin patterns that forced operators to expose backend infrastructure to potential DDoS vectors. The mechanism relies on an automatically deployed Elastic Network Interface placed within the origin's private subnet to enable secure data transfer. This architecture supports both centralized and distributed deployment models, allowing networking teams to isolate edge traffic from core application logic effectively.
Eliminating Attack Vectors with Private ALB Access
Making the Application Load Balancer private removes the ability for attackers to bypass WAF rules by discovering the public domain. This mechanism forces all ingress traffic through the CloudFront edge, where Layer 7 protection policies apply before any packet reaches the origin. Operators integrate AWS Shield Standard and AWS Shield Advanced to mitigate DDoS threats within this zero-trust Architecture.
Continuous deployment in CloudFront enables zero-downtime migration by routing a specific percentage of traffic, such as 15%, to a staging distribution with new private origins. This approach validates connectivity without disrupting production flows. Removing public access eliminates the ability to test origins directly from outside the VPC, requiring operators to rely on internal bastion hosts or specific test distributions. The drawback of this operational constraint is measurable in added complexity for debugging network paths.
Network teams see a reduction in undifferentiated heavy lifting related to managing custom header rotations and IP allow-lists. Security posture improves because the attack surface shrinks to only the CloudFront distribution points. Origin infrastructure remains invisible to port scanners and direct volumetric attacks. This architectural change fundamentally alters how teams validate application health during incidents.
Configuring Origin Groups and Layer 7 Protection
New origin groups require fresh configuration objects rather than modifying existing public origin mappings. Operators must delete legacy behavior rules and instantiate origin groups containing the new private endpoints to prevent routing failures during migration. This step often introduces latency spikes if traffic weights are not carefully managed across the transition window.
| Architecture Model | Origin Group Complexity | WAF Rule Scope |
|---|---|---|
| Centralized | High (cross-account RAM shares) | Global (single policy) |
| Distributed | Low ( | Local (per-distribution) |
Layer 7 defense demands AWS Shield Advanced paired with AWS WAF intelligent threat mitigation to block volumetric and application-layer attacks. Relying solely on standard protections leaves private origins vulnerable to sophisticated botnets targeting specific API paths. The Elastic Network Interface acting as the gateway enforces strict subnet isolation but does not inspect payload content.
Teams often overlook that infrastructure requirements for Regional API Gateways add unnecessary complexity compared to direct ALB integration. Quota limits on ENIs per subnet can stall large-scale deployments if not pre-calculated.
AWS RAM Mechanics for Cross-Account VPC Origin Sharing
Cross-account VPC origin sharing requires AWS Resource Access Manager to bridge network boundaries between distinct security domains. This mechanism decouples distribution management from origin hosting, allowing centralized networking teams to serve traffic for private APIs owned by development units. The November 2025 update specifically enabled this utility for multi-account organizations operating outside a single AWS Organization.
- Define the resource share in the owner account containing the private Application Load Balancer.
- Specify target principal AWS accounts or organizational units for access.
- Accept the pending invitation in the consumer account holding the CloudFront distribution.
- Verify IAM permissions allow the consumer to reference the shared VPC origin.
| Share Scope | Trust Model | Operational Overhead |
|---|---|---|
| Intra-Organization | Automatic acceptance | Low |
| External Account | Manual acceptance required | High |
Increased coordination latency represents the price of this architecture; a missed acceptance step blocks traffic flow entirely until resolved. Unlike public origins, private VPC endpoints lack DNS resolution outside the shared context, making manual verification of the resource share state mandatory before cutover. Failure to align security group rules with the ENI ingress requirements results in immediate 502 errors that standard health checks cannot distinguish from application failures.
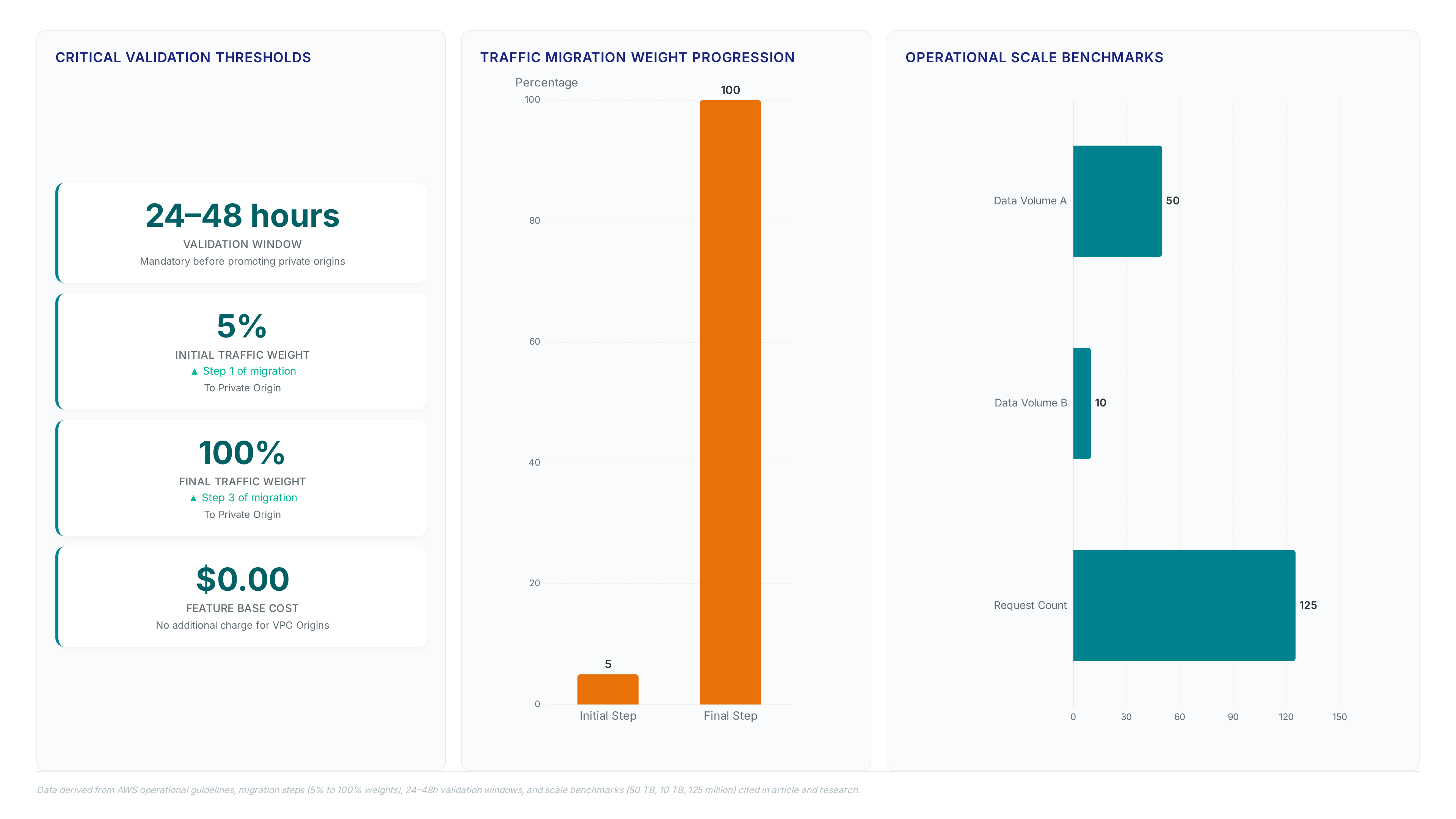
This conservative start allows engineering teams to observe 4xxErrorRate and 5xxErrorRate metrics without risking widespread user impact. The continuous deployment mechanism in CloudFront requires manual promotion to increase weights beyond this initial threshold.
Initial release in November 2024 limited VPC origins to AWS Commercial Regions only, requiring explicit verification before migration planning begins. Operators must confirm regional availability because unsupported Availability Zones cause immediate deployment failures during resource provisioning. This constraint forces a preliminary audit of target infrastructure locations against the published commercial region list.
- Verify that the target AWS Region supports private origin endpoints using the official launch documentation.
- Confirm that existing Origin Shield configurations remain valid when switching from public ALBs to private ENIs.
- Ensure Layer 7 protection mechanisms like AWS Shield Standard are active on the distribution before altering routing logic.
- Test connectivity from a within-VPC instance to validate application readiness prior to exposing the endpoint to CloudFront.
Legacy architectures relying on public load balancers can transition smoothly since Origin Shield continues to function with private VPC origins without reconfiguration. The continuity of caching layers prevents cache-fill storms during the cutover window. Skipping the regional support check results in opaque API errors that delay troubleshooting. Teams should prioritize validating traffic shifting. Failure to sequence these steps correctly exposes the origin to direct internet traffic before security groups are fully tightened.
Executing a Zero-Downtime Migration to Private VPC Origins
Blue-Green Deployment Mechanics for Zero-Downtime VPC Migration
CloudFront continuous deployment creates a staging distribution to validate VPC origin. This blue-green approach isolates risk by mirroring the primary configuration while keeping the legacy public path active. Operators configure the staging environment with private endpoints, ensuring the backend remains sealed from direct internet access during testing.
- Initialize the staging distribution pointing to the new private Application Load Balancer.
- Attach a continuous deployment policy using Header-based type to route specific test requests.
- Switch to Weight-based type once header tests confirm stable ALB.
- Promote the staging configuration to production after the validation window closes.
Validating IAM permissions and regional availability prevents immediate deployment failures before configuring private endpoints. Operators must confirm account access to manage both CloudFront and Amazon VPC resources, as missing privileges halt the creation of necessary network interfaces. This prerequisite step ensures the migration workflow proceeds without authorization errors during the initial provisioning phase.
Regional support requires explicit verification because the initial release limited VPC origins. Attempting to deploy in an unsupported Availability Zone triggers resource provisioning errors that block the entire migration path. Teams should audit target infrastructure locations against the published commercial region list before proceeding.
The underlying architecture demands specific resource types, where CloudFront VPC Origins. Alternative designs using Regional API Gateways often introduce unnecessary complexity through additional VPC Endpoints and Target Groups.
| Requirement | Validation Action | Failure Mode |
|---|---|---|
| IAM Permissions | Verify manage access to CloudFront and VPC | AuthorizationException during creation |
| Region Support | Confirm Commercial Region availability | ResourceNotReady in unsupported AZ |
| Subnet Type | Ensure private subnet assignment | Public exposure of origin interface |
Neglecting this audit forces operators to dismantle partially configured environments when regional mismatches surface.
Operational Durability and Troubleshooting Common VPC Origin Errors
Diagnosing 5xx Error Rates and Origin Connection Timeouts
High 5xxErrorRate numbers usually mean CloudFront cannot complete a TCP handshake with the private Elastic Network Interface inside the origin subnet. Security groups blocking ingress from the CloudFront service prefix cause this specific failure even when routing tables look correct. Operators separate application logic faults from network timeouts by watching OriginLatency spikes next to HTTP status codes.
| Metric | Technical Meaning | Immediate Action |
|---|---|---|
| 5xxErrorRate | Origin server failed to process request | Verify application health inside VPC |
| Connection Timeout | TCP handshake failed before completion | Audit security group ingress rules |
| 4xxErrorRate | Client request contained invalid syntax | Review WAF logs and header formatting |
Persistent timeouts often show that WebSocket traffic for real-time apps exceeds the idle timeout set on the load balancer. Private endpoints lack direct internet exposure so external diagnostic probes return no data. The 4xxErrorRate tracks client-side malformation instead of origin connectivity loss. Confusing these signals leads teams to chase non-existent application bugs while a missing firewall rule remains the actual culprit.
Monitoring Performance Metrics During the 24–48 Hour Validation Window
Teams must watch 5xxErrorRate spikes constantly during the mandatory 24–48 hour validation window before promoting private origins. Shifting weighted traffic. This mechanism compares OriginLatency baselines between the public legacy path and the new private ENI route. Deployment patterns indicate that removing undifferentiated heavy lifting.
A hidden cost appears here because operators often forget that while the VPC Origin feature carries no premium, standard hourly charges for private underlying resources persist without public IP offsets. Disabling the continuous deployment policy forces a session reset and invalidates active user states across the fleet. Full promotion requires confirming zero timeout errors across all Availability Zones.
Layer 7 DDoS Risks When Exposing Private ALBs Without WAF Rules
Removing public IPs eliminates discovery yet exposes private ALBs to Layer 7 floods if intelligent threat mitigation stays disabled. Attackers using compromised internal credentials or misconfigured peering can still target the origin directly. Compute exhaustion drives significant unplanned costs from emergency scaling events.
The shift to private origins mitigates bypass risks yet introduces a dependency on edge-layer filtering since the origin no longer sees full request volume for local rate limiting. AWS Shield Standard protects distributions but operators must explicitly enable AWS WAF to block sophisticated application-layer patterns before they reach the backend. Public setups sometimes allow broad access through security groups by accident. The feature: origin privacy. Failure to configure rules here results in 5xx errors as the private load balancer collapses under unchecked HTTP floods. InterLIR recommends treating the private subnet as a trusted zone only after validating that WAF policies drop malicious payloads at the edge.
About
Alexander Timokhin, CEO of InterLIR, brings deep expertise in IT infrastructure and IP addressing to the complex discussion of migrating Amazon CloudFront origins. While InterLIR specializes in optimizing global network availability through its IPv4 marketplace, Timokhin's daily work involves solving critical connectivity challenges that directly align with secure CloudFront architectures. His background in managing network resources and ensuring clean BGP routing provides a unique perspective on why organizations must secure origins within private Amazon VPC environments. As leaders strive to balance centralized versus distributed models, Timokhin's experience in strategic planning for network scalability offers valuable insights into protecting origin servers like ALBs and EC2 instances. By using his understanding of global network architecture, this article guides technical teams in implementing reliable, private origin configurations that enhance security without compromising the efficiency that defines modern cloud delivery systems.
Conclusion
Scaling VPC Origins exposes a critical operational friction point: the 15-minute ENI provisioning window creates a hard ceiling on deployment velocity that standard CI/CD pipelines cannot ignore. While removing public IPs secures the perimeter, it shifts the entire burden of Layer 7 defense to the edge, meaning any gap in WAF rule coverage immediately translates to backend compute exhaustion rather than simple connectivity failures. The hidden cost here is not the feature itself, but the unplanned scaling events triggered when intelligent threat mitigation lags behind traffic patterns. Organizations must treat the edge as their primary compute shield, not just a delivery mechanism.
Adopt this architecture only if your team can enforce automated WAF policy validation before any distribution update reaches production. Do not attempt a full cutover until you have verified zero timeout errors across all Availability Zones during a staged rollout. If your current security operations cannot sustain real-time rule tuning, delay migration until Q3 when automated policy testing matures.
Start by auditing your existing security groups this week to ensure private ALBs accept traffic exclusively from CloudFront-managed prefix lists, rejecting all other ingress immediately to prevent lateral movement risks before enabling the VPC Origin feature.
Frequently Asked Questions
There is zero additional charge for enabling this specific feature beyond standard rates. You pay the base cost of $0.00 for the VPC Origin capability itself while maintaining normal data transfer fees.
The deployment window required for Elastic Network Interface provisioning takes exactly 15 minutes. Operators must coordinate this specific timeframe carefully during maintenance windows to ensure successful private connectivity.
You should route a specific percentage of traffic, such as 15%, to a staging distribution with new private origins. This validates connectivity without disrupting live production user sessions.
Yes, you can use cross-account VPC sharing to connect distributions in one account to origins in another. AWS Resource Access Manager facilitates this secure routing without requiring public internet exposure.
No, you can eliminate public IPs entirely by connecting distributions directly to internal Application Load Balancers. This architecture renders your origin infrastructure invisible to the public internet and potential DDoS attacks.
