Protective DNS blocklists fail schools often
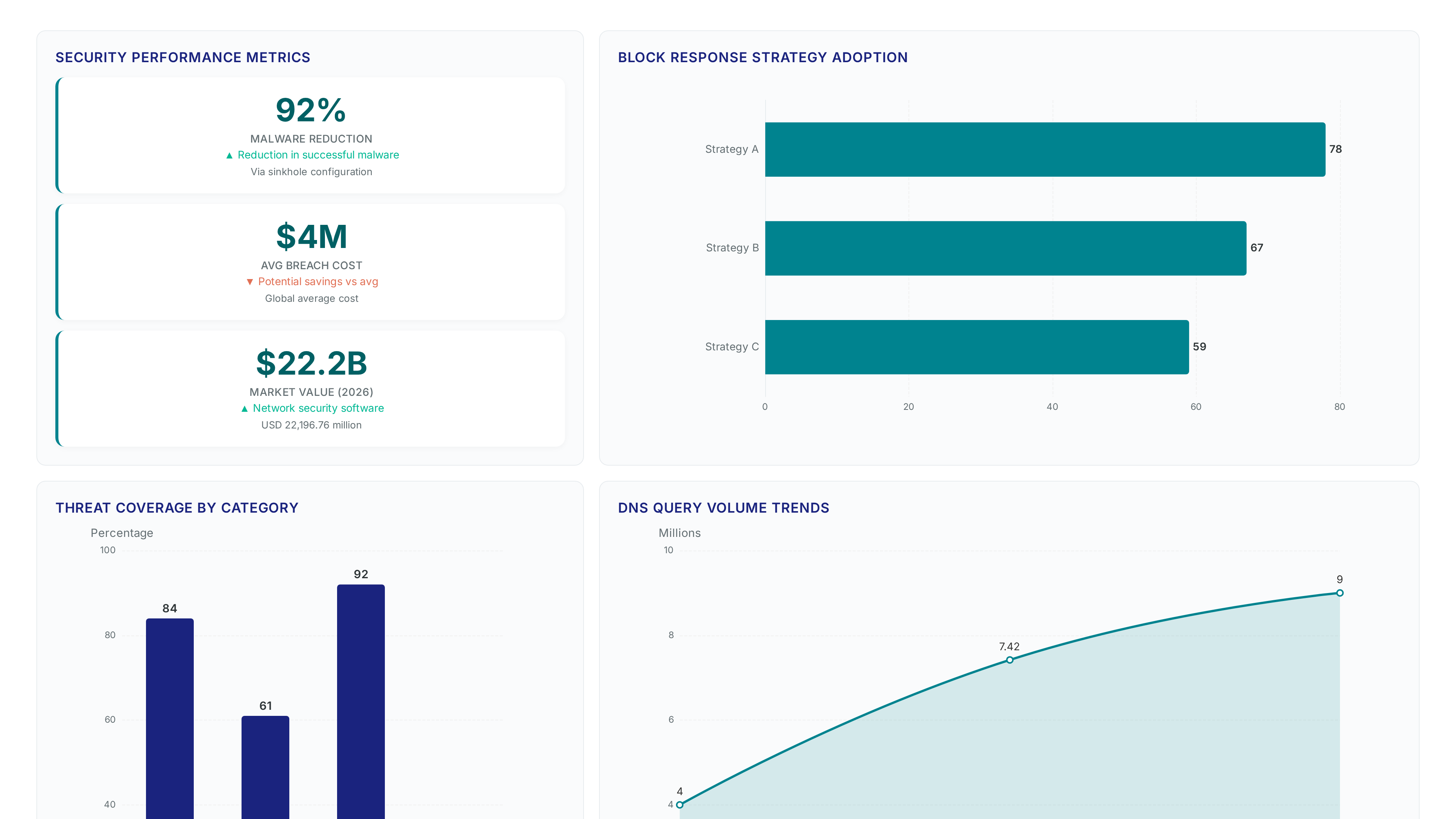
78% of enterprises deploy network security software, yet most treat Protective Domain Name System (PDNS) as a set-and-forget utility. Branden Palacio's March 2026 analysis exposes a critical gap: while 67% of organizations run intrusion detection systems, almost none audit the curation transparency of their threat sources.
PDNS acts as a recursive resolver, intercepting malicious domain requests before a connection ever forms. This differs fundamentally from deep web filtering. Palacio notes that Research and Education Networks (RENs) supporting K-12 and higher education face unique friction points due to massive query volumes and diverse user demographics. Blocklists vary wildly in threat categorization and update frequency. A "one-size-fits-all" list works for a home router; it breaks a university campus.
This guide dissects blocklist overlap across three major threat sources to reveal conflicting definitions of malicious activity. We walk administrators through strategic selection of commercial and open lists tailored for high-volume academic traffic. Finally, we expose the limits of DNS filtering alone, specifically its inability to counter DoH bypasses or direct IP access without complementary firewall rules.
The Role of Protective DNS in Securing Research and Education Networks
Protective DNS functions as a recursive resolver filtering domain names against threat lists before connection. This architecture inspects resolution requests within Research and Education Networks supporting K-12 and higher education. The mechanism intercepts queries to verify destinations against curated blocklists of known malicious content. Operators configure the resolver to return NXDOMAIN or a sinkhole address upon match detection. Such prevention reduces malware deployment success rates notably according to federal pilot data. Blocklist curation varies widely in scope and maintenance frequency across providers. A single family network requires different filtering granularity than a large academic campus.
NXDOMAIN Responses and Sinkholing Malicious Domains
NXDOMAIN responses refuse resolution outright, signaling non-existence to the client resolver immediately. This mechanism restricts users by denying access to domains matching preconfigured blocklists without revealing internal network topology. Operators often prefer this method for static threats where investigation offers no additional intelligence value. Attackers receive instant feedback, allowing rapid rotation to new command-and-control infrastructure. Advanced implementations may instead sinkhole a domain, delaying threat execution while capturing traffic for analysis. Redirecting requests to an internal IP address enables security teams to inspect active threats before they propagate.
Alternative Response Pages Versus NXDOMAIN Refusals
Alternative response pages direct users to internal notifications rather than returning silent resolution failures. This method informs users in the education sector that access denial stems from security policy, not network error. Silent NXDOMAIN refusals indicate non-existence, effectively hiding the block from non-technical observers. Home network configurations often prefer silent drops to minimize support tickets from confused family members. Academic environments frequently require visible block pages. The operational cost involves user experience versus attacker reconnaissance capabilities during incident response.
| Feature | Alternative Page | NXDOMAIN Response |
|---|---|---|
| User Feedback | Explicit block notification | Silent failure message |
| Attacker Intel | Confirms active filtering | Mimics dead domain |
| Support Load | Higher initial query volume | Lower visible friction |
| Deployment Context | Managed academic networks | Residential gateways |
Visible pages generate immediate helpdesk tickets when legitimate sites false-positive, increasing operational overhead instantly. Silent refusals allow malware to retry indefinitely without alerting the endpoint user to the specific cause. Selecting the correct mode depends on whether the priority is user education or stealthy threat containment.
Analyzing Blocklist Overlap and Curation Transparency Across Threat Sources
TreeTop Passive DNS Monitoring and Blocklist Reconstruction
TreeTop processes packet capture files from the June 2025 collection window to reconstruct domain-IP relationships into tree-based data structures. This passive DNS monitoring tool parses raw traffic to map observed queries against threat feeds without active probing. Operators feed pcap files into the engine, which then indexes domains for rapid matching against curated lists. The methodology aligns with services provided by REN-ISAC using similar infrastructure to collect passive data for the research community. Reconstruction logic groups unique domains by their resolved addresses, creating a hierarchical view of resolution patterns. Advanced PDNS solutions require this depth to align with real-time threat intelligence across endpoints. Static blocklists alone fail to capture the flexible nature of modern malicious infrastructure. The cost of internal infrastructure weighs against potential breach costs of $9 million in the U. S. Justifying complex tooling. TreeTop output reveals gaps where commercial curation misses niche academic threats or vice versa. Blind reliance on a single feed leaves networks exposed to unlisted variants. Analysis requires cross-referencing multiple sources to minimize overblocking while maintaining security posture. The process transforms raw packets into actionable intelligence regarding filter coverage. Missing this step risks deploying incomplete defenses across large user demographics.
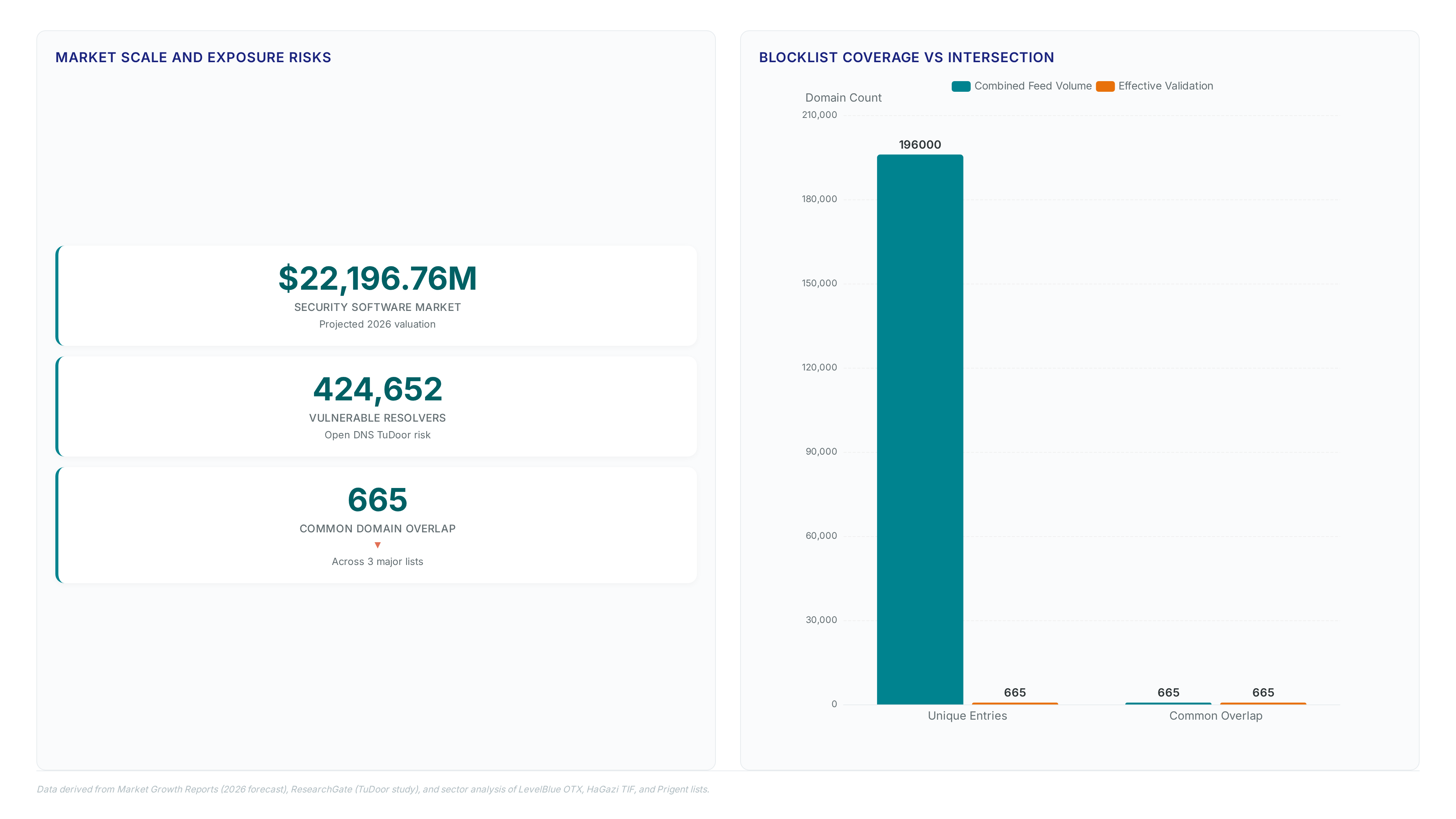
Quantifying OTX, TIF, and Prigent Overlap in 890 Million DNS Packets
The 890 million packet dataset yielded 27 OTX matches, 2,907 TIF hits, and 236 Prigent Malware detections with zero triple overlap. TreeTop reconstructed these domain-IP relationships from raw pcap files to measure intersection rates across the three distinct threat feeds. Observed traffic revealed no simultaneous matches between OTX and Prigent Malware, confirming the pre-measurement gap persists in live REN environments. Such divergence forces operators to stack multiple lists, increasing processing load without guaranteeing broader malicious domain coverage. The lack of consensus suggests that relying on a single commercially curated feed leaves significant blind spots in threat detection.
| Blocklist | Unique Matches | Pairwise Overlap |
|---|---|---|
| OTX | 27 | 3 (with TIF) |
| TIF | 2,907 | 27 (with Prigent) |
| Prigent | 236 | 0 (with OTX) |
Operators must weigh the cost of maintaining multiple feeds against the risk of missing niche threats hidden in smaller lists. Basic DNS filtering often relies on static blocklists, whereas advanced solutions integrate deeper threat intelligence This integration gap explains why TIF dominated the match count while OTX contributed minimally to the observed block events. Deployment of private recursive servers allows teams to optimize resolution speed while reducing exposure to external threats. However, the market value of network security software implies that paid alternatives offer curation depth free feeds cannot match alone. No single source provides complete visibility, necessitating a hybrid approach that balances coverage breadth with resolver performance constraints.
Curation Transparency Gaps and AI-Driven Threat Categorization Uncertainty
Limited transparency into curation strategies prevents operators from auditing why specific educational domains face blocking. Black-box AI-driven categorization introduces uncertainty because machine learning models often lack explainable logic for flagging benign research sites as malicious. This opacity creates a dangerous tension between aggressive threat hunting and the academic need for open information access. Operators cannot tune false positives without seeing the underlying taxonomy or selection criteria used by vendors. Reliance on automated systems increases the risk of overblocking legitimate healthcare or university resources during model training phases. Conversely, underblocking occurs when novel attack vectors fall outside the narrow patterns recognized by static AI models. Advanced solutions attempt to mitigate this by aligning with deeper threat intelligence The result is a fragmented defense posture where blocklist overlap fails to guarantee thorough coverage. Educational institutions face unique risks when government-grade filters misclassify student projects as phishing campaigns. Blind trust in automated feeds leaves critical infrastructure vulnerable to both censorship errors and undetected breaches. The cost of silence is measurable in lost research time and compromised security perimeters.
Strategic Selection of Commercial and Open Blocklists for Academic Environments
Defining Sector-Specific Blocklist Curation for Education
Sector-specific blocklist curation for education rejects banking-grade filters that ignore academic resource accessibility requirements. General commercial lists often lack the nuance needed for Community Anchor Institutions where research demands open access to emerging domains. A configuration optimized for financial fraud prevention frequently misclassifies legitimate university repository traffic as malicious phishing attempts. Openly available blocklists provide minimal insight into the criteria leading to the classification of a malicious site, creating operational blindness. Operators cannot audit taxonomy decisions when vendors hide their selection logic behind proprietary algorithms. The market for network security software reached 22,196.
Operators fix low blocklist coverage by stacking feeds with minimal intersection rather than seeking redundant validation. The study found only 665 domains appeared across LevelBlue OTX, HaGazi TIF, and Prigent lists simultaneously, proving that single-feed reliance leaves massive gaps. Proven selection requires calculating union size instead of assuming overlap guarantees safety.
| Feed Source | Total Entries | Observed Matches |
|---|---|---|
| LevelBlue OTX | 180,528 | 27 |
| HaGazi TIF | 496,328 | 2,907 |
| Prigent Malware | N/A | 236 |
High entry counts do not translate to detected threats within specific Research and Education Network traffic patterns. TIF captured the majority of observed malicious queries despite OTX holding commercial curation status. Institutions must prioritize feeds matching their actual user behavior over raw list volume or market reputation. Relying on static lists ignores the threat intelligence. The financial stakes justify this analytical rigor the the average global cost of a data breach was approximately $4 million during the period studied. Network teams should deploy passive measurement tools to validate feed efficacy before committing to a blocking policy. Blindly aggregating lists increases processing overhead without improving security posture if the feeds target different threat verticals.
Automated classification without human review amplifies ambiguous decision-making, causing legitimate research domains to trigger NXDOMAIN responses incorrectly. Black-box algorithms within commercial feeds often lack explainable logic, forcing operators to guess why a specific university repository appears on a blocklist. This opacity prevents security teams from auditing the taxonomy used to flag benign sites as malicious threats. Stakeholders investing in the broader network protection software market face uncertainty when vendor curation strategies remain hidden behind proprietary AI models. Academic institutions requiring open access cannot tolerate aggressive filtering that mimics banking-grade fraud prevention protocols. Basic DNS filtering relying on static lists fails to adapt, yet flexible AI updates introduce unverified changes to threat categorization daily. Researchers at Tsinghua University demonstrated that opaque implementation details significantly complicate security assessments for large-scale deployments. The tension between maximizing malicious domain detection and minimizing false positives remains unresolved without transparent criteria. Operators must prioritize feeds offering clear selection logic over those promising automated efficiency through undisclosed machine learning processes. Blind reliance on vendor AI risks severing access to necessary educational resources under the guise of protection.
Deploying PDNS Services to Minimize Overblocking and Maximize Coverage
Defining PDNS Response Mechanisms for REN Security
REN operators must choose between NXDOMAIN refusals and alternative resolution pages to align with institutional incident response workflows.
- Configure the resolver to return a non-existent domain code when strict denial prevents user confusion about site availability.
- Direct blocked queries to an internal IP address hosting a resolution page that explains the security policy to students and faculty.
- Validate that negligible query latency
Forensic capability depends entirely on this selection since sinkholing via alternative resolution captures traffic for analysis while NXDOMAIN deletes the evidence immediately. Academic networks serving Community Anchor Institutions often prefer visible blocks to educate users rather than silently failing connections. Silent failures increase helpdesk tickets because users cannot distinguish between a typo and a security block without visual feedback. Infoblox. Overblocking risks rise when operators select NXDOMAIN without auditing blocklist taxonomy against academic resource requirements.
Deploying Sinkholing to Delay Threat Execution in Campus Networks
Directing malicious queries to a controlled sinkhole IP captures command-and-control traffic for forensic analysis rather than dropping connections immediately.
- Configure the resolver to rewrite matching A records to an internal monitoring address instead of returning NXDOMAIN errors.
- Enable detailed logging on the sinkhole server to record source IPs and timestamps for every captured request.
- Verify that this response rewriting introduces negligible query latency
This approach transforms the DNS layer into a passive sensor, providing visibility into infected hosts that would otherwise remain undetected by standard blocking methods. Immediate threat neutralization stops malware instantly yet destroys evidence of the infection vector. Intelligence gathering requires a different path. Sinkholing delays execution just enough to identify compromised devices within the diverse K-12 demographic before containment procedures begin. Commercial blocklists often lack the specific context required for academic environments, making local traffic analysis necessary for tuning false positives. The technique uses the recursive nature of PDNS to intercept threats while maintaining the open access principles vital to educational missions.
Implementation: Validation Checklist for Sector-Specific Blocklist Curation
Administrators must validate blocklist overlap against local traffic logs before enforcement to prevent accidental blocking of academic resources.
- Extract unique domain queries from the last week and cross-reference them with candidate feeds to identify false positives.
- Prioritize lists showing minimal intersection, as high overlap often indicates shared curation errors rather than improved security coverage.
- Configure resolvers to log NXDOMAIN responses separately for audit trails without impacting negligible query latency
- Integrate real-time threat intelligence
| Validation Step | Required Action | Risk Mitigated |
|---|---|---|
| Traffic Baseline | Compare allow-list against blocklist | Prevents research downtime |
| Feed Analysis | Reject sources with high similarity | Avoids redundant filtering |
| Response Test | Measure resolver timing under load | Maintains user experience |
Blindly adopting large commercial feeds increases overblocking probability because size does not correlate with relevance for K-12 environments. InterLIR recommends manual review of any domain categorized by opaque AI models before global deployment. Ntime Feed Analysis Reject sources with high similarity Avoids redundant filtering R Large volumes of data overwhelm staff without clear taxonomies. Specific academic needs demand custom curation strategies. Generic lists fail to address unique research domains. Local context determines success or failure in deployment scenarios.
About
Nikita Sinitsyn serves as a Customer Service Specialist at InterLIR, bringing eight years of dedicated experience in telecommunications support and IP resource management. His daily work involves managing RIPE and ARIN database operations, enforcing KYC procedures, and monitoring spam control metrics, which provides him with unique insight into the critical importance of network security. This hands-on background makes him uniquely qualified to discuss Protective Domain Name System (PDNS) solutions, as he routinely addresses the consequences of malicious traffic and compromised IP reputations. At InterLIR, a Berlin-based marketplace specializing in secure IPv4 address redistribution, Nikita ensures that clients maintain clean BGP announcements and safe network environments. His practical exposure to threat mitigation directly connects to the article's focus on safeguarding Research and Education Networks, illustrating how reliable DNS filtering is necessary for maintaining the integrity and availability of modern digital infrastructure.
Conclusion
Scaling Protective DNS reveals that operational fatigue becomes the primary vulnerability, not technical failure. As organizations layer multiple threat feeds, the cost of managing false positives eventually exceeds the savings from prevented breaches. The current market trend shows widespread adoption of network security tools, yet most deployments fail because they prioritize coverage volume over contextual accuracy. This mismatch creates a hidden tax on IT staff who must constantly untangle legitimate academic traffic from aggressive, generic blocking rules.
Organizations must shift from indiscriminate feed aggregation to curated validation within the next six months. Do not deploy any new blocklist without first establishing a baseline of your specific environment's query patterns. If a vendor cannot demonstrate how their taxonomy aligns with your unique operational profile, reject the integration regardless of their threat count claims. Security efficacy depends on precision, not the sheer size of the data ingested.
Start by auditing your current resolver logs this week to identify the top fifty blocked domains that generated internal support tickets. Cross-reference these against your active feeds to calculate your specific false positive rate. Use this data to immediately disable any source contributing a significant share of noise to your environment before expanding your security perimeter.
Frequently Asked Questions
Blind aggregation increases false positives without guaranteeing better security coverage. Research shows that 78% of enterprises deploy security software, yet few scrutinize curation transparency, leading to operational friction in diverse academic environments.
Only 665 entries occur simultaneously across all three analyzed threat sources. This minimal intersection proves that varying scope leads to disagreements on threat definitions, requiring strategic selection rather than simple aggregation.
Approximately 55,451 domain names appear in both the TIF and Prigent Malware lists. Such high redundancy suggests that combining these specific sources offers diminishing returns for filtering unique malicious activity.
PDNS acts as a recursive resolver intercepting requests before connections establish. While 67% of organizations use intrusion detection, PDNS provides a distinct, lighter layer specifically designed to block malicious domain resolution instantly.
The resolver returns an NXDOMAIN response or redirects traffic to a sinkhole address. This immediate refusal prevents malware deployment success rates from rising, effectively stopping connections to known malicious infrastructure.
