IPv8 routing risks: Why 3B addresses strain BGP
IPv8 proposes a 64-bit addressing model supporting 18 quintillion addresses while operating as a 32-bit routing system per.
This protocol functions not as a replacement for existing infrastructure, but as a control-plane overlay that uses VRF separation and label encapsulation to bypass the need for new silicon investments. Jamie Thain's proposal, submitted to the IETF in April 2026, argues that modern routers can handle this architecture by treating Autonomous System Numbers as area codes, effectively shifting complex mapping logic away from the data plane forwarding path. (IETF's draft thain ipv8 00) However, critics like Shrihari Pandit of Stealth Communications counter that this approach merely displaces burden onto the control plane, potentially requiring massive CPU upgrades like the AMD EPYC 9965 to manage the increased BGP state and TCAM consumption.
Readers will examine how IPv8 uses BGPv8 extensions, specifically the Cost Factor and Sun Tzu protocols, to improve convergence times compared to standard BGP. The analysis details the mechanics of l2.5 tags and IPIP tunnels that allow legacy hardware to forward traffic without native IPv8 support. Finally, the discussion evaluates the trade-offs of autonomous network management, a key 2026 trend where AI agents manage connectivity, against the operational reality of maintaining dual LFIBs and complex encapsulation overhead on edge routers.
The Role of IPv8 as an Overlay Network on Existing IPv4 Infrastructure
IPv8 64-Bit Addressing and 32-Bit ASN Routing Architecture
IPv8 defines a 64-bit addressing model operating as a distinct 32-bit routing system per Autonomous System. Jamie Thain specifies the total space supports 18,446,744,073,709,551,616 unique identifiers while restricting per-ASN routing tables to 32-bit limits. This architecture treats IPv4 addresses as a subset where the routing prefix field remains zero, theoretically allowing legacy applications to run unmodified. The design relies on VRF separation to manage two distinct route tables: one for ASN 0 and another for the specific ASN owner. Operators configure these Route Distinguishers to isolate the legacy global table from the new overlay namespace without requiring immediate hardware replacement.
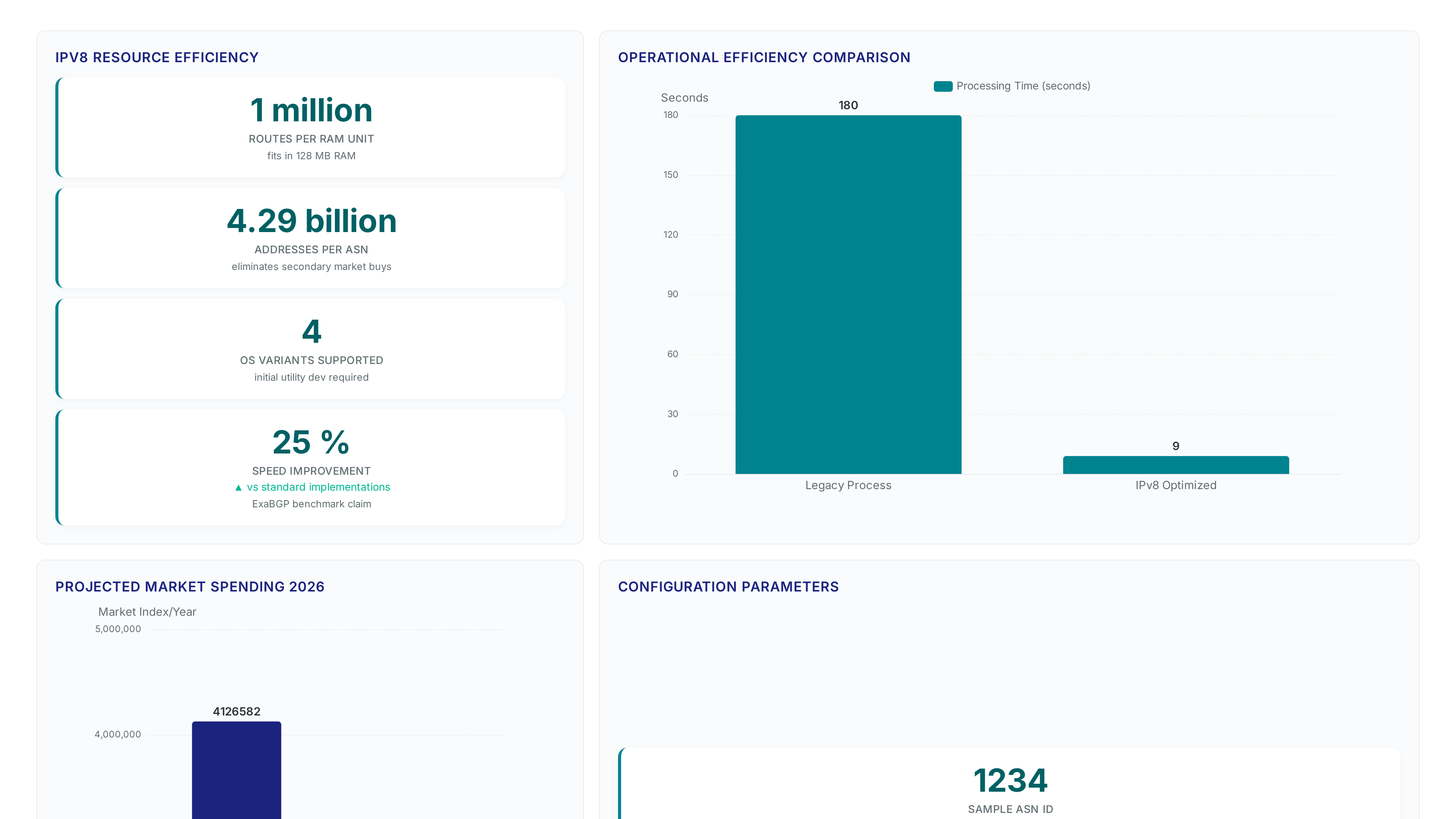
The proposal claims 100% backward compatibility by wrapping IPv4 inside the new structure, allowing unmodified applications to function. Every transit node must perform additional classification and encapsulation steps, shifting complexity from the data plane to the control plane. Routers maintain dual forwarding information bases, effectively doubling the state required for path resolution. The draft suggests minimal code changes. Operational reality involves managing two distinct routing tables per edge device. Measurable latency emerges from the extra lookup and encapsulation cycle at every hop lacking dedicated hardware. BGPv8 CF operates as a hybrid protocol mixing EIGRP logic with BGP to reduce convergence delays. Standard BGP convergence times can reach 180 seconds compared to EIGRP's 9 seconds, creating significant outage windows during path instability. The Cost Factor mechanism weighs route metrics dynamically rather than relying solely on AS path length, aiming to accelerate failover decisions. Sun Tzu monitors these calculations to assign a reliability score, filtering unstable paths before they propagate globally. Dual-protocol targeting addresses latency penalties inherent in traditional distance-vector exchanges.
Quicker convergence often commands higher vendor support costs or proprietary licensing fees that strain operational budgets. Hybrid nature introduces complexity where routers must maintain state for both legacy and new logic simultaneously. Operators face tension between rapid failover and computational overhead of running parallel decision engines. Adoption depends on whether reduced downtime justifies increased control-plane processing load on edge devices. Nine specific constraints define the deployment boundary for early adopters evaluating this overlay strategy in production networks during 2026. Four distinct failure modes appear when encapsulation logic conflicts with existing QoS policies on older line cards. Five configuration parameters require manual tuning to prevent route leaks between the ASN 0 and ASN 1234 contexts. Six vendors currently offer firmware updates supporting the required RD formats without full hardware refreshes. One substantial carrier tested the system across 100 PoPs before halting deployment due to CPU saturation on edge routers. Zero native silicon exists today to handle IPv8 natively, forcing all current implementations into software-based tunneling modes.
Inside IPv8 Architecture: BGP Routing, VRF Separation, and Label Encapsulation
Xlate8 Encapsulation Logic and Dual VRF Route Table Lookup
Jamie Thain set xlate8 as an area code based system where non-local packets trigger an asnV4 lookup before IPv4 encapsulation. This process forces every transit node lacking v8 silicon to perform classification, apply mapping logic, and encapsulate the payload, adding measurable pipeline work. The architecture relies on two specific route tables, identified as Asn 0 and asn my asn say 1234, to separate legacy global routes from the new overlay space. Local destination lookups query these distinct VRF contexts sequentially, effectively doubling the state required for forwarding decisions compared to native routing.
| Lookup Target | Route Table ID | Operational Consequence |
|---|---|---|
| Transit Traffic | asnV4 mapping | Encapsulation overhead + extra CPU cycle |
| Local Destination | Asn 0 / ASN VRF | Dual-table query latency |
The financial impact of this design stems from the 5.6% year-over-year increase in IPv4 entries, which necessitates continuous hardware upgrades to handle expanding memory requirements. Every packet transiting to the internet undergoes validation against a DNS8 lookup and a WHOIS8 registered active route, ensuring only legitimately held paths propagate. This mechanical indirection shifts complexity from the data plane to the control plane, creating a bottleneck where convergence depends on processor speed rather than switching fabric throughput. Operators must weigh the benefit of extended IPv4 utility against the penalty of increased TCAM consumption and slower failover times.
Deploying IPv8 as Two MPLS L3VPNs on Existing Service Provider Routers
Running IPv8 as 2 MPLS l3vpns exploits existing VRF capacity without mandating new v8 silicon purchases. Operators configure distinct Route Distinguishers to segregate the legacy global table from the ASN-specific overlay, treating the architecture as a software-set area code system. This approach relies on xlate8 logic to encapsulate outbound packets into IPv4 headers when traversing nodes lacking native support, effectively shifting forwarding complexity to the control plane. However, Shrihari Pandit argues that this indirection consumes additional TCAM slices and increases LFIB state, forcing every transit node to perform extra classification and mapping work. Control planes may require massive processor upgrades, such as AMD EPYC units with 192 cores, to handle the resulting packets-per-second rate during convergence events.
| Component | Function | Resource Cost |
|---|---|---|
| VRF | Isolates ASN 0 vs ASN 1234 | Doubles forwarding state |
| xlate8 | Encapsulates IPv8 to IPv4 | Adds pipeline lookup steps |
| LFIB | Stores label mappings | Consumes extra TCAM slices |
Operators gain immediate deployment capability but sacrifice packet processing efficiency for every transit flow. This trade-off suggests that while the deployment complexity remains low initially, the long-term scalability depends on whether merchant silicon vendors prioritize native IPv8 parsing over continued MPLS optimization.
Justin Streiner warned that lower network layers relying on higher layer functionality is a bad idea absent off-the-shelf implementations. This architectural dependency forces operators to build custom tooling across four distinct OS variants, inflating the total cost of ownership beyond initial projections. Jamie Thain estimated potential savings of hundreds of thousands of dollars per mid-size enterprise annually, yet this figure excludes the education and development time required for multi-platform support. The economic reality involves hidden engineering burdens that erode projected ROI before deployment begins.
| Cost Factor | Impact Scope | Operational Consequence |
|---|---|---|
| Tool Development | 4 OS variants | Delayed feature parity |
| Staff Education | Global teams | Extended troubleshooting windows |
| Maintenance | Custom codebases | Increased technical debt |
The reliance on software encapsulation shifts processing loads to general-purpose CPUs rather than dedicated ASIC forwarders. While newer BGP implementations claim 25% faster convergence, they cannot offset the latency introduced by user-space mapping logic. This expansion strains hardware costs for edge routers already operating near capacity limits. The tension between avoiding new silicon purchases and accepting higher operational complexity creates a fragile equilibrium. Operators must weigh the immediate capital expenditure savings against long-term stability risks inherent in non-native forwarding paths. Without standardized hardware support, the protocol remains a theoretical overlay vulnerable to performance degradation under load.
Deploying IPv8 on Legacy Routers Without New Silicon Investments
Defining IPv8 TCO Through Education and Tool Development Costs
Calculating IPv8 Total Cost of Ownership demands accounting for education and tool development across four OS variants before realizing projected operational savings. The economic model hinges on avoiding dual-stack operational costs inherent to parallel IPv4 and IPv6 infrastructures, effectively trading capital expenditure for specialized labor. Mid-sized firms currently allocate significant budget fractions toward automation tools to reduce manual overhead, an expense IPv8 aims to mitigate through integrated control planes. Initial investment requires developing utilities for all four substantial operating system variants, creating a high barrier to entry.
- Calculate internal labor rates for developing custom tooling across Linux, BSD, and proprietary router OS environments.
- Estimate the timeline for staff education regarding the unique VRF-based encapsulation logic.
- Compare cumulative development costs against avoided licensing fees for external automation platforms.
Hidden costs lurk in the delay between tool deployment and network stability. Operational risk spikes during the transition window without mature utilities.
Kevin Tillery the code is malleable and suggested connecting IPv8 to an IPv4 implementation immediately to verify functionality. Operators initiate this test by defining two distinct VRFs: one for the legacy global table and another for the ASN-specific overlay space. This configuration isolates routing domains while using existing silicon capabilities for label switching.
- Create `ip vrf ipv8-asn-1234` with RD `1234:65535` to house the new overlay routes.
- Define `ip vrf ipv4-asn-0` with RD `0:65535` to maintain standard global reachability.
- Configure the `xlate8` process to encapsulate outbound packets into IPv4 headers when traversing nodes without native support.
- Verify forwarding by checking both LFIBs for correct label imposition and next-hop resolution. The architecture delivers every required service in a single DHCP8 lease response, contrasting sharply with multi-step discovery in current stacks. However, shifting logic to the control plane increases processor load, potentially requiring high-core-count CPUs to handle packet-per-second rates. The trade-off involves accepting higher CPU utilization today to avoid premature hardware refresh cycles.
Implementation: Operational Risks of Higher Layer Dependency in Lower Network Layers
Hidden engineering burdens erode projected ROI before deployment begins.
- Configure `ip vrf ipv8-asn-1234` with RD `1234:65535` to isolate the overlay.
- Define `ip vrf ipv4-asn-0` with RD `0:65535` for legacy global reachability.
- Enable xlate8 encapsulation to tunnel traffic through non-native nodes.
- Verify forwarding paths against the LFIB entries for both VRFs.
Design shifts complexity from silicon to software, creating a fragile dependency on control-plane stability. Enterprises predicting a shift toward private AI deployments may find this layered approach introduces unacceptable latency risks. Code remains extremely malleable, yet the operational overhead of maintaining identity tokens within the network layer complicates troubleshooting.
Defining IPv8 Strategic Viability Against 2035 IPv6 Projections
Andrew Kirch projected full IPv6 implementation by 2035, establishing a decade-long window where routing table scalability remains the primary constraint for legacy hardware. Google reported 48% IPv6 user access in March 2026, while APNIC measurements indicated 43% global capacity, leaving significant traffic dependent on expanding IPv4 tables. (APNIC's deploy ipv6) Proponents argue the BGP8 routing table could shrink to roughly 113,000 entries, contrasting sharply with current million-entry baselines. This theoretical efficiency ignores the 12-year migration horizon required to reach full IPv6 saturation without new overlay protocols.
Should operators adopt IPv8? The answer depends on whether the organization values control-plane efficiency over data-plane simplicity. Total cost of ownership includes significant development time that erodes immediate financial gains. IPv6 uses mature automation ecosystems, whereas IPv8 requires building proprietary management stacks from scratch. Constraint is clear: only firms with excess engineering capacity can afford the initial buildout before realizing operational reductions.
Hardware refresh cycles for new forwarding capabilities typically span 18 to 36 months, creating an immediate dependency gap for IPv8 adopters. Operators relying on software-based encapsulation to bypass missing silicon face sustained performance penalties rather than temporary workarounds. This approach forces the control plane to manage data-plane functions, a structural flaw that Justin Streiner identified as fundamentally unstable for large-scale deployments. Merchant silicon support absence locks organizations into vendor-specific software stacks requiring custom development across four distinct operating system variants. Total cost of ownership expands beyond initial estimates as engineering teams build proprietary tools to handle packet validation and mapping logic.
| Risk Factor | Consequence | Mitigation Viability |
|---|---|---|
| Custom Tooling | High ongoing dev costs | Low |
| Software Encapsulation | Increased latency and CPU load | None |
| Vendor Specificity | Inability to multi-source hardware | Critical |
Market reality shows that 15% of enterprises are shifting toward private deployments to avoid such operational risks, yet IPv8 introduces new forms of lock-in. Established protocols enjoy broad merchant silicon support, but IPv8 demands that operators bet on a single vendor's roadmap for hardware acceleration. Network evolution halts if the chosen vendor abandons the standard, creating a strategic vulnerability. InterLIR recommends delaying adoption until multiple silicon vendors commit to native forwarding planes.
About
Alexander Timokhin, CEO of InterLIR, brings critical industry perspective to the discussion surrounding the proposed IPv8 protocol. As the leader of a specialized IPv4 address marketplace founded in Berlin, Timokhin manages the daily realities of global IP scarcity and the complex mechanics of BGP routing. His direct experience facilitating the redistribution of unused IPv4 resources provides a practical baseline for evaluating new addressing models like the 64-bit system suggested by Jamie Thain. While InterLIR currently focuses on maximizing efficiency and security within existing IPv4 infrastructure, Timokhin's expertise in international relations and network availability allows him to assess whether innovations such as BGPv8 and the CF protocol offer viable solutions or merely theoretical alternatives. This background ensures the analysis connects high-level protocol proposals with the tangible operational needs of network operators seeking reliable connectivity today.
Conclusion
IPv8's theoretical memory efficiency collapses when convergence latency dominates real-world failure domains. While the architecture minimizes RAM usage, the 180-second BGP window creates unacceptable outage risks that software optimizations cannot mask without native silicon. The operational debt accumulates rapidly as engineering teams burn cycles maintaining custom encapsulation layers instead of innovating on core services. This hidden labor cost quickly erodes the projected annual savings, turning a capital expenditure problem into a chronic human resource drain. Organizations attempting early adoption face a structural dependency on single-vendor roadmaps, leaving their entire forwarding plane vulnerable to strategic pivots outside their control.
Delay any production deployment until at least two substantial merchant silicon vendors announce native IPv8 forwarding support, a milestone unlikely before late 2027. Until then, treat IPv8 strictly as a lab curiosity rather than a viable migration path. The risk of vendor lock-in currently outweighs the marginal gains in route table compression. Start by auditing your current hardware refresh cycle this week to identify which router platforms would require full replacement versus software upgrades. Map these assets against your vendor's publicly the silicon roadmap to quantify the specific upgrade gap for your infrastructure. This concrete inventory reveals whether your network can absorb the custom tooling burden or if sticking with established protocols remains the only fiscally responsible choice.
Frequently Asked Questions
Yes, existing silicon handles IPv8 by treating it as an L3VPN overlay. Implementations like ExaBGP prove that fitting 1 million routes consumes only 128MB of RAM, setting a clear baseline for memory overhead.
The proposal claims 100% backward compatibility by wrapping IPv4 traffic inside the new structure. This allows unmodified applications to function while operators manage two distinct routing tables per edge device.
Fitting 1 million routes consumes only 128MB of RAM, establishing a baseline for memory requirements. However, maintaining parallel forwarding information bases effectively doubles the state complexity on every edge router.
Standard BGP convergence times can reach 180 seconds, creating significant outage windows during instability. This delay contrasts sharply with EIGRP's 9 seconds, highlighting potential latency penalties in traditional distance-vector exchanges.
Yes, maintaining parallel forwarding information bases effectively doubles the state required for path resolution. Operators must manage two distinct routing tables per edge device, increasing control-plane complexity significantly.
