Neoclouds bottleneck H100 clusters with weak nets
Half of audited neoclouds fail to support optimal H100 bandwidth requirements, creating a severe bottleneck for enterprise.
The explosive growth of the neocloud sector masks a critical infrastructure deficit where networking capabilities lag dangerously behind compute scaling. While Omdia reports that providers have successfully deployed GPUs, their study of 50 distinct neoclouds reveals that networking infrastructure is now the primary constraint on performance. Enterprises chasing capacity are ignoring the fact that moving data securely across distributed geographies requires far more than raw processing power.
This article dissects why AI infrastructure investments are stalling due to inadequate backends and details the specific architectural failures plaguing current offerings. Readers will learn how cost-cutting measures lead to insufficient backend bandwidth, leaving systems unable to handle the 400Gbit/s demands of modern clusters. We will also expose the hidden operational risks of adopting these immature platforms before network supercycle spending resolves these fundamental flaws. Ignoring these technical debts threatens to turn projected efficiency gains into expensive liabilities.
The Role of Neoclouds in Modern AI Infrastructure
Defining Neoclouds: From Bitcoin Mining to AI Infrastructure
Former Bitcoin mining facilities operated by IREN and Cipher now house high-density GPU clusters, repurposing legacy power assets to bypass traditional hyperscaler procurement delays. These neocloud entities currently command 17% of AI infrastructure investment. The transition relies on redeploying hundreds of megawatts of existing power contracts to support dense compute racks without new civil engineering. Yet raw compute availability masks significant networking infrastructure deficits that threaten workload stability. An April 15, 2026 audit of 50 providers revealed that 43% lack internal engineering teams capable of managing complex AI networking demands.
In this sector, the definition of a cloud on-ramp often excludes direct peering exchanges. Over half of providers rely solely on public internet transit. This architectural choice creates a bottleneck where backend bandwidth drops by 50% compared to optimal H100 server configurations using eight 400Gbit/s NICs. Enterprises evaluating these providers must verify IP asset ownership, as 46% control only small IPv4 blocks insufficient for traffic localization. Gartner projects neoclouds will capture 20% of the market by 2030, yet current IP transit durability remains fragile with one in five operators depending on a single upstream carrier.
Optimal H100 server performance demands 3,200Gbit/s backend bandwidth via eight 400Gbit/s NICs. This configuration prevents saturation during distributed training phases where collective communication patterns dominate traffic flow. Such hardware choices directly degrade model convergence time, turning network topology into the primary limiter of GPU utilization. Neoclouds differentiate themselves by shipping new hardware first and tuning networks specifically for AI workloads rather than general versatility. Hyperscalers often lag in procuring these specific high-density GPU configurations due to broader inventory mandates. The cost of this specialization appears in reduced latency for all-reduce operations but introduces risk if the underlying fabric lacks redundancy.
Fragility strikes when 47% of all IP transit relationships sit under the control of just 15 major providers. A single upstream failure cascades instantly through neocloud environments lacking redundant IP transit agreements. Enterprises must verify that providers possess diverse backbone connections before committing production workloads to these platforms. The cost of this oversight is measurable in lost compute cycles during network outages.
IP Transit Durability and the Top 15 Provider Bottleneck
One in five neoclouds relies on a single IP transit provider, creating an immediate single point of failure for AI training clusters. IP transit durability defines the capability to maintain connectivity despite upstream link failures, yet concentration among Tier 1 backbone owners like Arelion, Cogent, and Lumen restricts path diversity. Unlike general web traffic, AI workloads demand lossless Ethernet to prevent packet drops that stall model synchronization across distributed GPUs.
The distinction between Tier 1 and Tier 2 providers becomes operational rather than theoretical when evaluating redundancy. Tier 1 owners possess global reach without purchasing transit, whereas Tier 2 carriers must buy capacity, introducing potential choke points during congestion events. Enterprises adopting Multi-Site Redundant architectures often find neoclouds unable to provision disjoint paths because the underlying transit market lacks sufficient competitor density. Dependence on a narrow supplier base limits the ability to engineer true geographic diversity for critical data flows.
| Backbone Tier | Transit Dependency | Risk Profile for AI Workloads |
|---|---|---|
| Tier 1 | None (Settlement-free) | Low latency, high concentration risk |
| Tier 2 | Purchases upstream capacity | Higher latency, variable congestion |
Operators must verify that providers maintain Silicon One architecture compatibility to handle bursty gradient updates without head-of-line blocking. The cost of ignoring this vetting process is measurable in stalled training jobs rather than mere connectivity loss.
Neoclouds use 191 Internet Exchanges to establish direct peering, bypassing public internet latency for distributed AI training. Frankfurt's De-CIX alone handles 10% of total port capacity, concentrating traffic to reduce hop counts between compute clusters. This architecture supports model parallelism by minimizing I/O bottlenecks during gradient synchronization across geographies. Direct interconnection allows enterprises to save up to 70% on data egress rates compared to standard public routing.
Reliance on specific facilities introduces geographic single points of failure. Operators must balance low-latency gains against the risk of regional outages affecting multiple peers simultaneously. The limitation is physical: colocation density creates shared fate among competitors sharing the same meet-me room.
| Path Type | Latency Stability | Failure Domain |
|---|---|---|
| Public Transit | Variable | Global Backbone |
| Direct Peering | Deterministic | Facility Specific |
| Private Link | Fixed | Provider Edge |
Production workloads demand this redundancy because neoclouds often lack the mature internal teams found at established hyperscalers. Without diverse physical paths, a single fiber cut at a substantial exchange can stall global training jobs. The cost of such downtime exceeds the savings from optimized routing. Enterprises must verify that providers maintain non-redundant sites only for development, not production AI pipelines.
Direct Colocation Connections vs Public Internet Egress Costs
Direct physical interconnects deliver 60% savings on egress rates compared to public internet routing for AI clusters. This financial advantage stems from bypassing transit fees charged by upstream providers while securing deterministic latency paths. Operators achieve these gains by deploying single-mode fiber links that terminate directly within the colocation facility, eliminating variable hops across the public grid. The performance delta manifests most sharply during distributed training phases where consistent throughput outweighs raw bandwidth capacity.
| Metric | Direct Colocation | Public Internet Egress |
|---|---|---|
| Cost Structure | Fixed port fee | Per-gigabyte tiered pricing |
| Latency Variance | Sub-millisecond jitter | High fluctuation |
| Path Control | Static, dedicated circuit | Flexible, best-effort routing |
| Failure Domain | Isolated link fault | Shared backbone congestion |
The operational burden shifts to the enterprise, which must manage physical layer specifications including transceiver types and fiber modes. Unlike hyperscalers offering managed gateways, neocloud connections often require manual provisioning of 100GBASE-LR4 optics to sustain 400 Gb aggregate speeds. This complexity creates a tension between cost efficiency and engineering overhead. Teams lacking in-house fiber expertise risk extended outage windows during hardware swaps or re-patching events.
The strategic implication forces a choice between capital expenditure on dedicated circuitry versus operational expenditure on variable transit. Enterprises must weigh the certainty of fixed costs against the flexibility of pay-as-you-go models when scaling GPU fleets.
Training and inference demand will hit 200 gigawatts by 2030, exposing enterprises to severe liability when providers cannot scale infrastructure to match signed commitments. Contracts executed in 2024 and 2025 face renewal in late 2026, precisely when supply bottlenecks threaten to breach service level agreements. Over a third of operators explicitly minimize contractual liability for network uptime, shifting performance risk entirely onto the customer during critical AI training windows. This legal asymmetry creates a dangerous gap between expected GPU availability and actual delivered capacity.
Enterprises must validate transit diversity before signing contracts, as one in five neoclouds relies on a single IP transit provider. This configuration creates an immediate single point of failure that jeopardizes distributed training jobs. Scrutinizing suppliers requires looking past raw GPU counts to assess network durability and financial viability against the $186 billion market forecast.
| Risk Factor | Validation Check |
|---|---|
| Transit Path | Confirm multiple upstream providers beyond the top 15 |
| Liability | Reject contracts minimizing uptime accountability |
| Sovereignty | Verify data handling meets local compliance statutes |
Hidden costs emerge when providers lack in-house skills to manage complex routing policies during outages. The talent gap forces operators to accept higher latency or packet loss while waiting for external consultants. Enterprise agreements signed previously come up for renewal in late 2026, shifting use to buyers demanding production-grade guarantees.
- Absence of redundant peering exchanges increases vulnerability to regional fiber cuts.
- Small IPv4 blocks limit traffic localization and routing control options.
- Minimized contractual liability shifts all performance risk to the customer.
Trusting a neocloud for AI workloads demands proof of financial stability alongside technical specs. The cost of ignoring these checks exceeds the savings from discounted compute rates.
Strategic Framework for Evaluating Neocloud Networking
Defining Full-Stack Ownership vs API-Only Neocloud Models
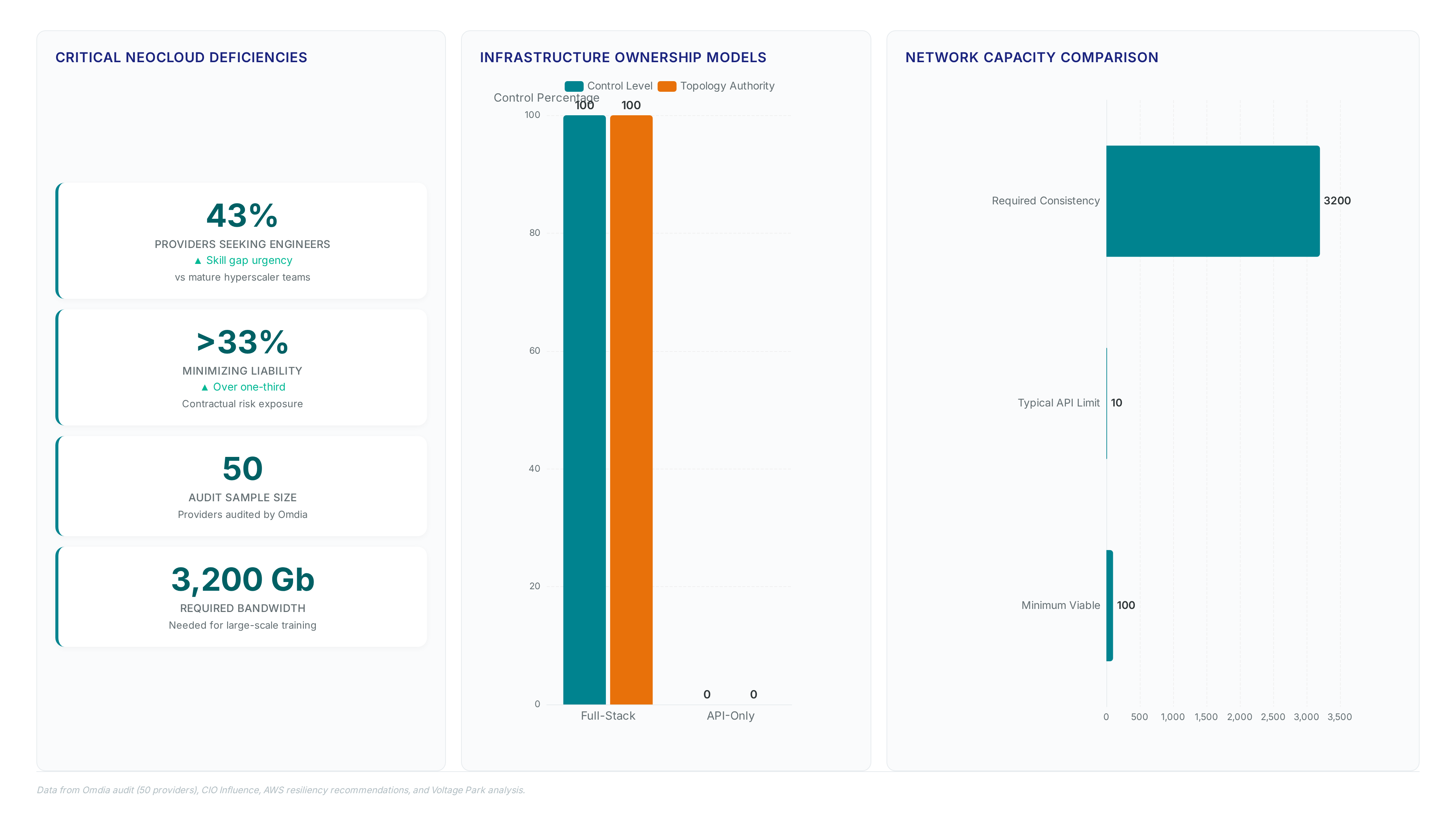
Full-stack ownership dictates control over data centers, software, hardware, power, and cooling, whereas API-only models merely rent GPUs in colocation facilities. This structural divergence determines whether an enterprise can engineer deterministic backend fabric performance or must accept shared transit constraints. Providers like Nscale exemplify deep vertical integration, owning the entire stack from ground to cloud to eliminate upstream dependency. Conversely, API-layer operators lack authority over physical topology, forcing traffic through public exchanges where latency fluctuates wildly.
Renting compute without owning the interconnect prevents optimization of lossless Ethernet protocols required for distributed training. Enterprises face a binary choice between architectural sovereignty and commoditized access. Those selecting API-only models inherit the routing policies of facility landlords, unable to tune AS path prepending or local preference values. Without ownership, operators cannot guarantee the 3,200Gbit/s bandwidth consistency needed for large-scale model training. The cost of this abstraction is measurable in stalled jobs and unpredictable egress fees. True durability requires owning the copper and fiber, not the virtual machine.
Validating Peering Capabilities Across 191 Internet Exchanges
Enterprises must verify direct interconnection maps rather than accepting vendor claims of global reach. Operators should demand proof of presence at specific colocation hubs where Equinix links the largest number of providers. Relying on public internet pathways introduces latency variance that disrupts synchronized gradient updates across GPU clusters.
Direct physical handoffs offer measurable economic and performance advantages over standard transit routing. Customers connecting via colocation facilities realize significant savings on data egress compared to public routing tables. The limitation remains that many smaller neocloud operators lack the capital to deploy redundant hardware across multiple exchange points.
| Validation Step | Required Evidence | Risk if Missing |
|---|---|---|
| IXP Presence | Port capacity logs at 3+ exchanges | Regional latency spikes |
| Transit Diversity | Contracts with >1 Tier 1 owner | Total site blackout |
| Peering Policy | Public route server participation | Asymmetric path failures |
Operators ignoring these checks face silent packet loss during high-volume inference windows. Network infrastructure constraints will ultimately dictate workload success regardless of available compute power.
Enterprises must demand proof of multi-vendor IP transit diversity, as one in five neoclouds relies on a single upstream provider.
Hidden costs emerge when providers lack in-house skills to manage complex routing tables under load. Many operators rush to partner or build infrastructure without mastering networking standards required for deterministic latency. The cost is measurable: traffic forced through public exchanges suffers jitter that breaks synchronized gradient updates. InterLIR advises verifying physical handoffs at colocation hubs rather than accepting virtual claims. Providers publishing a single per-GPU hourly rate often bundle substandard transit, masking the true expense of data egress. Enterprises facing contract renewals in late 2026 should treat network topology maps as binding deliverables. Failure to validate these assets exposes production workloads to silent packet loss during peak inference windows.
About
Alexander Timokhin, CEO of InterLIR, brings critical expertise to the discussion on neocloud readiness for AI networking. As the leader of a specialized IPv4 marketplace founded in Berlin, he manages the fundamental network resources required to scale distributed AI environments daily. The Omdia study highlights that while compute capacity has grown, networking infrastructure remains a severe bottleneck for neoclouds. Timokhin's work directly addresses this constraint by ensuring enterprises access clean, secure IP addresses necessary for reliable data movement across geographies. His deep experience in IT infrastructure and international business relations allows him to analyze why raw compute power is insufficient without reliable underlying network availability. At InterLIR, his team solves these exact availability problems through transparent resource redistribution. This practical background makes him uniquely qualified to evaluate why neocloud providers must prioritize network stability over mere processing speed to support the next-generation of artificial intelligence workloads effectively.
Conclusion
Rapid scaling exposes a critical fracture where raw GPU density collides with brittle network architecture. As neoclouds chase the projected $186 billion valuation, operational fragility will emerge as the primary constraint, not compute availability. Providers lacking deep engineering benches cannot sustain the deterministic latency required for massive cluster training, leading to silent performance degradation that standard SLAs fail to capture. The market will inevitably bifurcate between commodity brokers and true infrastructure partners capable of managing complex peering relationships without introducing jitter.
Enterprises must mandate full network topology disclosure by Q2 2026 before signing any multi-year commitments. Treat providers refusing to share physical handoff details as high-risk vendors regardless of their hardware specifications. This strict vetting window allows organizations to secure capacity before the inevitable consolidation weeds out under-capitalized operators who cannot support enterprise-grade traffic localization.
Start by auditing your current vendor's BGP routing tables against their advertised diversity claims this week. Request specific proof of non-overlapping upstream paths and verify these assertions through third-party looking glass servers immediately. This single technical validation step prevents future bottlenecks that no amount of additional GPU power can resolve.
Frequently Asked Questions
Nearly half of audited providers cannot manage complex AI networking demands internally. Specifically, 43% of the 50 neoclouds studied lack the necessary in-house engineering teams to support robust infrastructure.
Modern clusters demand massive backend throughput to prevent saturation during distributed training phases. Optimal H100 server configurations require exactly 3,200Gb of bandwidth delivered through eight distinct network interface cards.
Many providers control insufficient address blocks, causing traffic to route through suboptimal paths. Data shows that 46% of these entities only possess small IPv4 blocks inadequate for proper localization.
Reliance on public internet transit instead of direct peering exchanges creates severe performance bottlenecks. This architectural choice causes backend bandwidth to drop by 50% compared to optimal server configurations.
These specialized entities are rapidly capturing market share by repurposing legacy power assets for compute. They currently command 17% of total AI infrastructure investment while bypassing traditional procurement delays.
