Optical demand surge: Why copper fails AI clusters
Ciena's order backlog jumped more than $600 million sequentially, hitting $7.7 billion. This isn't a blip; it's proof that the optical network is now the primary bottleneck for AI scaling. We have moved past incremental upgrades. We are witnessing a fundamental opticalization of the data center where legacy copper and short-reach optics simply cannot support the density modern training clusters demand. The network is no longer a passive utility. It is the critical constraint defining AI infrastructure limits.
The shift from 400G to 800G deployments is reshaping interconnect strategies for hyperscalers in 2026. Enterprises must adopt managed optical strategies to survive a market that Ciena CEO Gary Smith calls "completely disrupted" and poised to double.
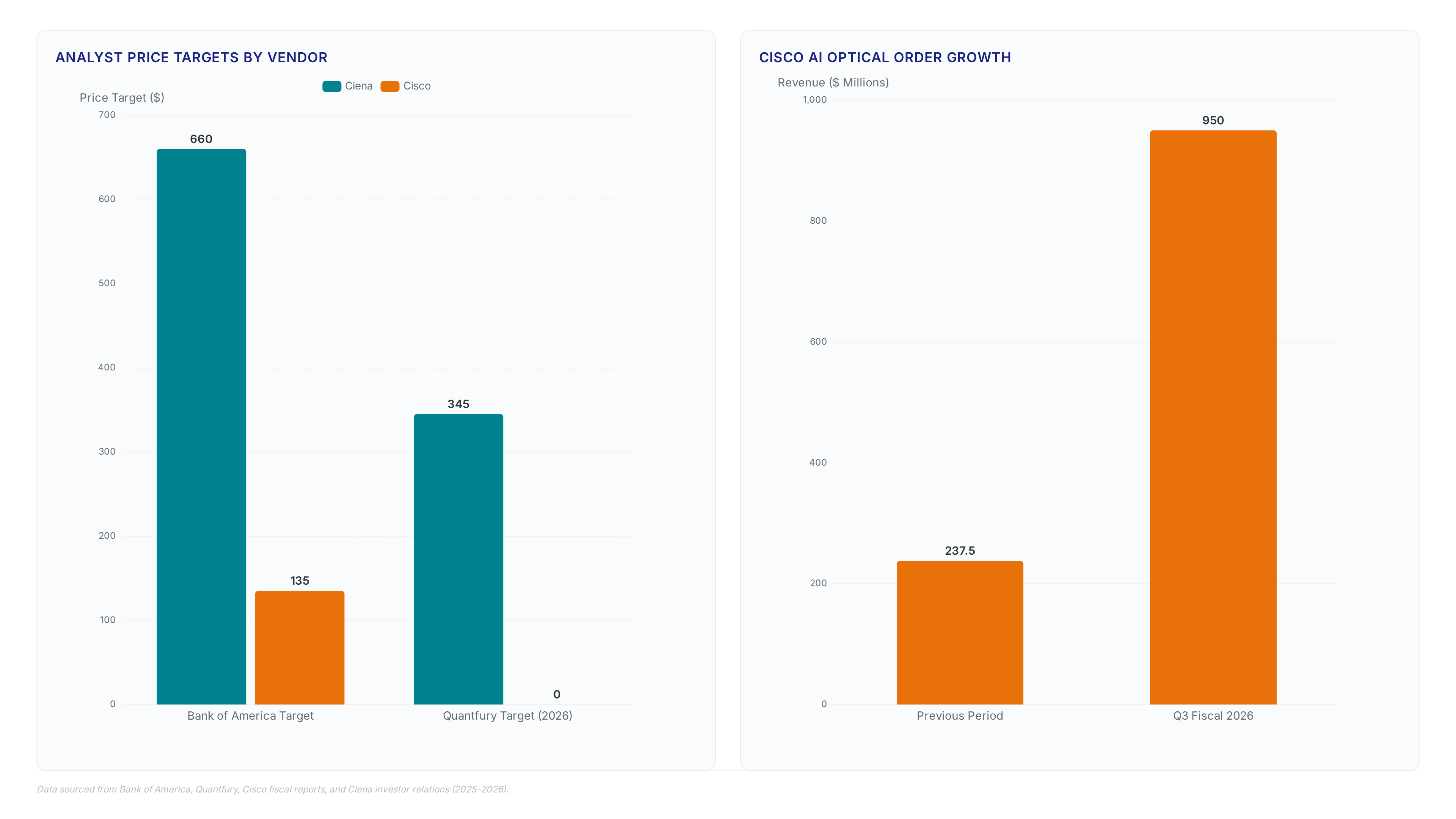
The financial signals are unambiguous. Ciena reported fiscal second quarter 2026 revenue of $1.57 billion, a 40% year-over-year jump driven entirely by hardware orders. Bank of America analysts note this trajectory implies sustained growth as service providers scramble to address scaling needs that only optical technology can satisfy. This is a structural reordering where network capacity dictates computational power.
The Role of Data Center Opticalization in Modern AI Infrastructure
Direct Connect Fiber-Optic Pathways Set
Physics is the enemy of copper. Direct connect pathways are private, dedicated fiber-optic links replacing electrical interconnects inside data centers because GPU densities and operating speeds now exceed the thermal and signal-integrity limits of copper backplanes. Electrical resistance and crosstalk degrade packet integrity at high frequencies, creating a hard ceiling. Gary Smith identifies this opticalization shift as inevitable.
This architectural change enables the scale across model. It links distributed AI training clusters that cannot fit within a single facility footprint. Implementing such high-speed packet-optical connectivity allows operators to treat geographically separated racks as a single logical compute pool.
Adoption becomes mandatory when cluster density breaks copper's signal integrity. Nvidia validates this by deploying initial Co-Packaged Optics solutions, moving production environments away from traditional pluggable transceivers. Electrical interconnects fail at these speeds due to thermal constraints and crosstalk. The market response is measurable; Cisco reported $950 million in AI optics orders during Q3 FY26, reflecting urgent demand for optical replacement of copper scale-up networks.
A transitional period persists where specific short-reach applications still apply electrical connections. Operators face a difficult choice between immediate deployment speed and long-term scalability, as mixing media types introduces complex interoperability testing. Legacy electrical patches cannot support the bandwidth required for distributed training across multiple facilities. This constraint drives the emerging scale across model, linking regional clusters that exceed single-site power envelopes.
| Connection Type | Max Proven Distance | Primary Limitation |
|---|---|---|
| Electrical Backplane | 100 meters | Transceiver cost |
Delaying this migration costs compute cycles during critical training windows.
InP-Based EML Supply Shortfalls Through 2027
Supply chains are breaking. A 17% shortfall in InP-based EML supply defines the 2026 production ceiling for high-speed optics. This component deficit prevents hyperscalers from fully replacing electrical connections with fiber despite urgent AI capacity needs. Supply constraints for these critical lasers persist into the second half of 2027, extending the timeline for full data center opticalization. Substantial fiber vendors like Corning and Sumitomo Electric face sold-out inventory situations that compound the semiconductor bottleneck.
| Constraint Factor | Impact Timeline | Affected Component |
|---|---|---|
| InP Wafer Capacity | Through H2 2027 | EML Lasers |
| Fiber Cable Inventory | Immediate | Direct Connect Paths |
| Assembly Yield | Q3 2026 | 800G Transceivers |
Operators must mix optical and electrical layers longer than planned, increasing latency variance across GPU clusters. Delayed EML availability specifically throttles 800G port density, leaving expensive compute resources underutilized while waiting for physical links.
Opticalization as the Only Scalable Technology for AI Clusters
Copper hits a wall. Optical technology remains the sole medium capable of addressing scaling up, out, and across at required speeds. Physical constraints on copper backplanes force a shift where direct connect pathways replace electrical interconnects inside high-density GPU racks. This transition supports the emerging scale across architectural model, connecting regional clusters that exceed single-facility power envelopes. Legacy electrical connections fail here due to signal attenuation and thermal limits at high frequencies.
The market size, historically stagnant between $12 billion and $13 billion for a decade, faces complete disruption and will likely double. Hyperscalers are deploying 800G links to interconnect distributed AI training sites. Rapid 800G deployments now replace 400G mainstream infrastructure to handle massive parameter synchronization. Nvidia and Broadcom validate this by shipping initial Co-Packaged Optics solutions for specific high-performance environments.
| Interconnect Type | Max Proven Distance | Thermal Constraint | Scalability Limit |
|---|---|---|---|
| Copper Backplane | 80 kilometers | Minimal | Multi-Site |
Transitioning to optical infrastructure introduces supply chain friction not present in mature copper markets. Component shortages delay full replacement schedules despite clear technical necessity. Operators must plan for extended lead times when designing multi-site training fabrics. The network becomes the primary power constraint for AI expansion.
Geographically dispersed GPU sites form virtual clusters to bypass local power ceilings, forcing optical networks to span regions rather than single campuses. Hyperscalers execute this by linking separate facilities into a unified logical training domain, treating distance as a secondary constraint to energy availability. The scale across model emerges as the primary architectural response, requiring distributed optical infrastructure to connect regional and multi-regional clusters efficiently. This approach shifts the bottleneck from rack density to wide-area latency management.
Implementation relies on rapid deployment of high-capacity wavelengths. Google validated the feasibility of flexible reconfiguration through its Apollo Project, deploying optical circuit switching as a backbone for all data center networks. Regional carriers like Singtel and SK Telecom now pivot to become enablers by deploying ultra-fast networking to bridge the AI compute-consumption gap in APAC.
| Constraint Type | Electrical Limit | Optical Solution |
|---|---|---|
| Power Density | Local grid capacity exceeded | Distribute load across sites |
| Signal Integrity | Copper attenuation at distance | Low-loss fiber transmission |
| Scalability | Fixed rack footprint | Elastic geographic expansion |
All four hyperscalers plan a step-function increase in capital expenditure, reaching a combined total of $600 billion to fund this distributed infrastructure. Coordination complexity remains the limitation; synchronizing training jobs across sites introduces latency variance that algorithms must tolerate. Operators cannot simply add bandwidth; they must redesign control planes to handle non-uniform path characteristics inherent in virtualized geography.
Gary Smith argued there has been under-investment in AI-related infrastructure relative to other elements, creating a massive financial exposure. This deficit forces hyperscalers to confront a $7.7 billion backlog that hardware vendors struggle to clear despite aggressive production ramps. The mechanism of failure involves a temporal mismatch where GPU compute capacity outpaces the physical deployment of coherent optics required to interconnect them. The cost of this catch-up phase is measurable in deferred training cycles, as incomplete network fabrics prevent full utilization of installed silicon. Accelerating opticalization incurs premium costs, but delaying it guarantees lost inference revenue. Capital injection cannot instantly resolve physical supply chain bottlenecks for specialized components. Hyperscalers must absorb higher unit costs to prioritize delivery, effectively paying a penalty for earlier budget allocation errors.
Managed Optical Fiber Networks (MOFN) Architecture for Hyperscalers
Hyperscalers outside the US now deploy managed optical fiber networks to bypass five years of service provider underinvestment. This architecture replaces standard direct connect models with service-provider-managed dedicated paths, enabling virtual clusters that span energy-constrained sites. Google validated this approach by deploying the Apollo Operators build these networks by securing dark fiber leases, installing coherent transceivers, and implementing automated wavelength provisioning software. The shift addresses physical limits where GPU density exceeds single-facility power envelopes.
Deployment economics favor low-cost connectors in mature markets to reduce total expenditure while maintaining signal integrity over long distances. However, Coherent Pluggable Optics (CPO) reliability in production remains unproven, delaying full replacement of copper in scale-up networks. Vendors compete on density, with Nokia claiming a 40-fold increase in amplifier capacity per rack to match hyperscaler footprint constraints. Without verified CPO performance, operators must maintain hybrid electrical-optical domains, increasing operational complexity. This strategy isolates the network layer from volatile GPU procurement cycles.
Executing Deployment Plans Against a $6.4 Billion Hardware Backlog
Time is running out. Approximately a significant share of the $6.4 billion hardware backlog ships within 12 months, dictating aggressive AI cluster interconnection timelines. Operations teams must align direct fiber installation schedules with this confirmed shipping visibility to avoid idle GPU assets. Deployment planners face a binary choice: secure component supply now or accept delayed cluster activation during the peak demand window.
Cost models for these deployments increasingly favor low-cost plastic optical fiber connectors in mature markets to mitigate rising component prices. This material shift reduces total project expenditure while maintaining signal integrity for short-reach intra-facility links. However, reliance on specific connector types introduces a single-source dependency that complicates emergency spares provisioning. Smaller operators risk displacement if they fail to lock in hardware allocation before inventory depletion occurs. The limitation of this approach is the reduced flexibility to alter network topology once components are assigned to specific build-outs.
Gross margin rising to a strong level with net income reaching a substantial amount signals vendor stability for scaling partners. Enterprises must verify that deployment suppliers maintain this financial health to prevent supply chain fractures during urgent build-outs. A partner lacking similar liquidity often fails to secure low-cost plastic optical fiber connectors needed for mature market cost reduction. The mechanism for validation requires auditing quarterly EBITDA growth, such as the 83.6% surge to $287.3 million observed in leading vendors. Operators must balance vendor profitability against the physical need for spectral efficiency in constrained racks.
Market Dynamics and Investment Viability in the Optical Networking Sector
Ciena's Focused Optical Strategy vs Broad Competitor Mixes
Focus wins. Ciena executes a pure-play optical networking strategy while Cisco maintains a diversified portfolio including significant non-optical assets. This divergence creates distinct risk profiles for hyperscalers selecting vendors for AI cluster interconnects. Ciena concentrates engineering resources exclusively on coherent optics and data-center interconnect solutions, whereas competitors balance optical innovation against legacy routing businesses. Nokia actively shifts from a traditional telco base toward the hypercloud market under CEO Justin Hotard, creating a hybrid model that lacks Ciena's singular focus.
| Dimension | Ciena Strategy | Cisco/Nokia Approach |
|---|---|---|
| Business Mix | Pure-play optical | Diversified portfolios |
| Geographic Reach | Selective markets | Global presence |
| R&D Allocation | Entirely optical focus | Split across domains |
Steve Alexander noted that Huawei is not a primary competitive threat in many regions because Ciena does not sell in every country where Huawei operates. This selective geographic strategy limits total addressable market but concentrates supply chain resources on accessible regions. Operators gain deeper vendor support in approved territories but face availability gaps in restricted zones. Accepting limited global coverage secures priority access to coherent transceivers during shortage periods. This financial density contrasts sharply with diversified competitors managing broader product mixes alongside optical assets. Pure-play vendors face geographic coverage gaps where non-participating rivals maintain entrenched positions. Hyperscaler infrastructure spending drives this momentum, yet reliance on a single technology vertical increases vulnerability to sector-specific downturns. InterLir analysts note that timing entries requires watching shipment conversion rates rather than total backlog size alone. Concentrated exposure offers higher beta during upcycles but reduces buffering capacity during demand contractions.
Vendor Positioning: Ciena Packet-Optical Depth vs Infinera Coherent Overlaps
Integration matters. Ciena unifies optical and packet technologies in the 6500 Packet-Optical Platform to integrate TDM with modern packet services necessary for hybrid AI networks. Infinera provides coherent optical technology but competes on specific service overlaps rather than unified platform depth. This architectural divergence dictates deployment velocity for hyperscalers scaling GPU clusters.
Microsoft used this unified model for a tiered optical business continuity architecture, contributing the design while Ciena supplied core transport technologies. Choosing discrete coherent layers carries a measurable cost: operators must procure separate packet switches, increasing physical rack space and power draw per terabit. Pure-play optical vendors avoid the dilution of engineering focus seen in diversified competitors managing legacy routing portfolios. InterLir recommends auditing vendor chassis diagrams for native packet slots before committing to multi-vendor optical overlays. Unified systems demand higher upfront capital expenditure despite lower total cost of ownership over five years.
About
Alexander Timokhin, CEO of InterLIR, brings critical perspective to the evolving optical network environment through his deep expertise in IT infrastructure and global IP resource management. While the article highlights Ciena's projections on optical market expansion driven by AI and data center scaling, Timokhin's daily work at InterLIR directly addresses the fundamental connectivity required to support such growth. As the leader of a specialized IPv4 marketplace, he understands that surging optical capacity is useless without sufficient IP addressing to route traffic effectively. His experience in redistributing unused IPv4 resources ensures that service providers and hyperscalers can fully apply new optical technologies without being bottlenecked by address scarcity. By connecting network availability with hardware scalability, Timokhin offers a complete view of how infrastructure layers must evolve together. His strategic focus on transparency and efficiency in resource allocation complements the industry's push toward massive opticalization, making him uniquely qualified to analyze these interdependent market shifts.
Conclusion
Power density per rack unit is the bottleneck, not just bandwidth. As hyperscalers deploy denser GPU arrays, the operational expense of cooling discrete coherent layers spirals, eroding the initial savings from modular purchases. The market must pivot from evaluating raw throughput to measuring energy-per-bit efficiency across the entire transport stack. Organizations should commit to unified packet-optical architectures for any new AI fabric deployment starting in Q4 2027, reserving discrete optical overlays only for legacy edge extensions where retrofit constraints dictate. This timeline allows vendors to mature their high-density chassis offerings while giving operators a clear window to renegotiate power contracts. Start by auditing your current colocation power allocation per rack this week, specifically identifying zones where cooling headroom falls below a critical threshold. Use this data to model the five-year energy penalty of adding external packet switches versus integrating native slots, ensuring your next capital request accounts for thermal limits rather than just port counts.
Frequently Asked Questions
Ciena's backlog surged by more than $600 million sequentially to reach new highs. This growth confirms the total order book now stands at $7.7 billion, proving optical capacity is the primary constraint.
The company reported fiscal second quarter 2026 revenue totaling $1.57 billion entirely from hardware. This figure represents a massive 40% year-over-year jump driven by urgent scaling needs.
Cisco reported $950 million in AI optics orders during the third quarter alone. This measurable market response reflects the urgent demand to replace copper scale-up networks immediately.
Electrical interconnects fail at high speeds due to strict thermal constraints and signal crosstalk issues. These physical limits force a mandatory transition to private fiber-optic pathways for dense clusters.
Dedicated fiber links allow geographically separated racks to function as one logical compute pool. Without this mesh, latency spikes during model synchronization would completely stall large-language-model training runs.
