Cloudflare Outage 2026: Why 1,100 Prefixes Failed
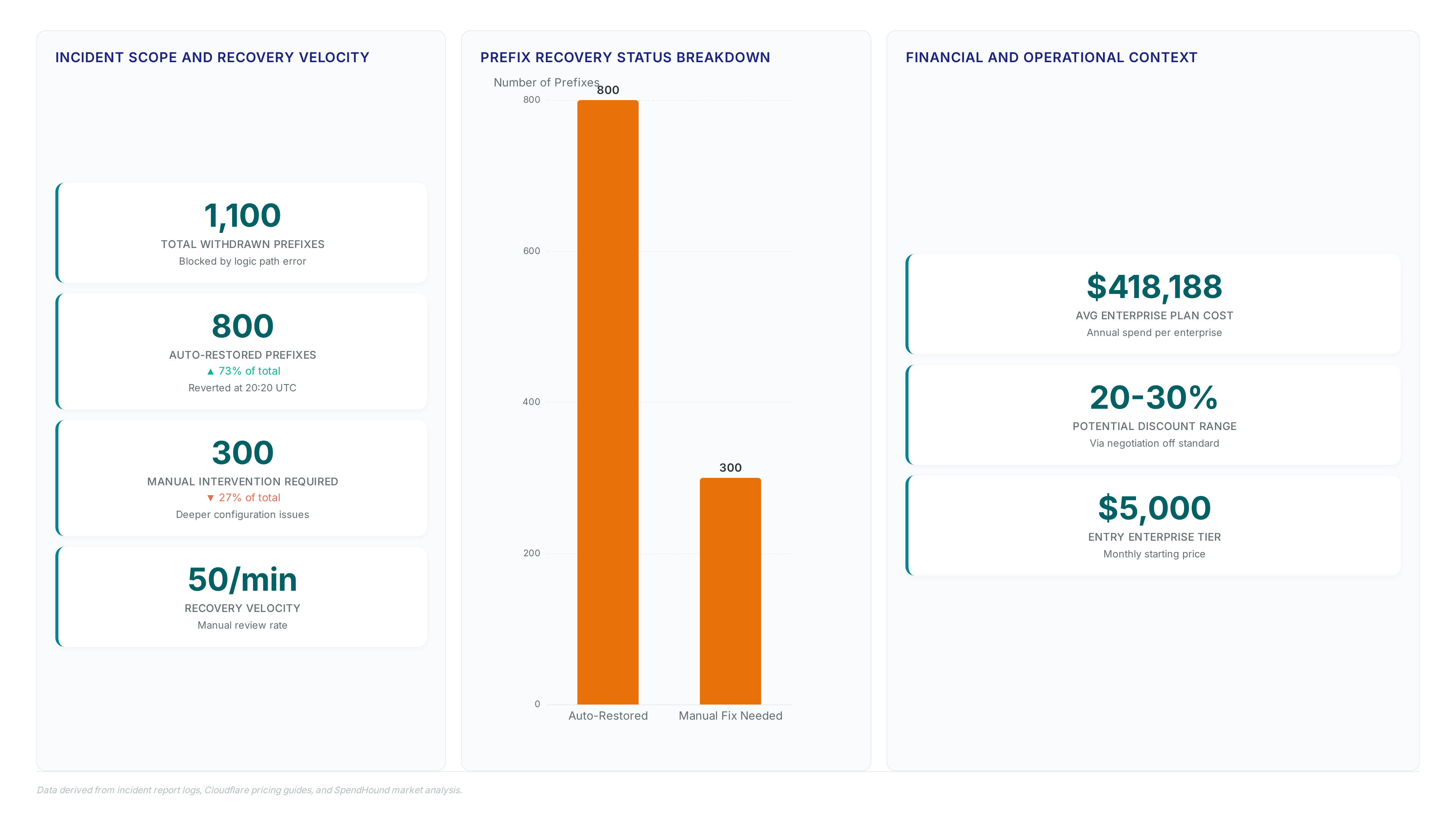
Cloudflare accidentally withdrew 1,100 BYOIP prefixes, breaking connectivity for a quarter of its bring-your-own-IP customers. (Cloudflare announces first quarter 2026 financial results)
This incident proves that automated network changes without rigorous fail-small safeguards remain a catastrophic single point of failure for modern internet infrastructure. While Gartner forecasts sovereign cloud spending will hit $80 billion in 2026, this outage demonstrates that digital sovereignty means nothing when BGP path hunting mechanics allow a simple configuration update to vanish critical routes. (Gartner's alternatives) The thesis is clear: reliance on complex addressing APIs creates hidden fragility where minor software bugs trigger massive service blackouts.
Readers will examine how Cloudflare's architectural dependence on BYOIP prefixes turned a routine management change into a six-hour global disruption. Finally, we analyze the dangerous gap between automated network changes and human response times, revealing why current fail-safe designs are insufficient for networks handling tens of millions of HTTP requests per second.
The Role of BYOIP and BGP in Cloudflare Network Architecture
BYOIP and BGP Prefix Withdrawal Mechanics
Bring Your Own IP (BYOIP) enables enterprises to import existing public IPv4 or IPv6 ranges into a provider's global edge while retaining ownership. The Bring Your Own IP (BYOIP) architecture allows organizations to use distributed security without renumbering their entire infrastructure. The Addressing API acts as the authoritative dataset for these addresses, with configuration changes immediately reflected across the network. When a withdrawal signal enters this system, routers update their BGP advertisements only after enough machines receive notifications from the API.
At 17:48 UTC on February 20, 2026, an automation bug withdrew 1,100 BYOIP prefixes, silencing a quarter of customer routes. Services relying on these withdrawn paths entered BGP Path Hunting states where traffic traversed networks searching for unreachable destinations. End users experienced connection timeouts while applications failed to proxy data through the edge. The disruption lasted 6 hours and 7 minutes, with engineers manually restoring configurations after automated re-advertisement attempts failed for roughly 300 prefixes. This event exposed a fragility in how the Addressing API
| Affected Component | Failure Mode | Restoration Method |
|---|---|---|
| Core CDN Security | Connection failures | Dashboard toggle |
| Magic Transit | Route invisibility | Manual edge push |
| 1.1.1.1 Web Portal | HTTP 403 errors | Configuration revert |
Operators evaluating whether to use BYOIP must weigh the convenience of retaining IP ownership against the risk of centralized control plane failures. The incident occurred on a network handling tens of millions of HTTP requests per second, illustrating how small configuration errors scale rapidly. Financial disclosures later revealed $639.8 million in quarterly revenue, yet the outage demonstrated that revenue scale does not immunize against prefix withdrawal cascades. Unlike local routing errors, this failure mode required global synchronization to repair, delaying recovery for customers unable to self-remediate. The dependency on a single authoritative dataset means that any logic error in the management plane instantly becomes a data plane outage.
Manual restoration scales poorly when failure domains expand beyond single racks. The Addressing API must evolve to enforce fail-small boundaries automatically rather than relying on operator vigilance during crises.
Addressing API Task-Runner Execution and Propagation Logic
The task-runner service independently executes data modifications without explicit user input, creating a silent failure vector. This background process queries the Addressing API using specific parameters to identify targets for deletion. A logic error occurs when the `pending_delete` flag lacks a value, causing the system to interpret the request as a command for all records rather than a filtered subset. The service then instructs edge machines to withdraw these prefixes immediately. BGP updates propagate across the network only after a threshold of machines receives these notifications, delaying visible impact while the internal state corrupts.
- The sub-task sends an HTTP GET request with an empty query parameter. 2.
Operators must recognize that automation speed inversely correlates with error containment when validation layers are thin. The Flagship feature flag service demonstrates how sub-millisecond evaluation can coexist with safety gates, a principle missing from the faulty deletion routine.
Staging environments failed to catch the bug because mock data lacked the specific task-runner execution patterns present in production systems. Initial code reviews validated the BYOIP self-service API process but missed the broken sub-process merged on 2026-02-05. The test suite assumed explicit user input, ignoring scenarios where background services execute changes independently. This gap allowed a query with an empty `pending_delete` parameter to return all prefixes instead of none. Operators managing complex edge deployments face similar risks when mock datasets do not mirror live traffic variance. Large enterprises securing network environments often struggle with this fidelity gap, as seen in Cisco ASA deployment 464.1/case_study_2_large_enterprise_firewall_vpn_and_ips_deployment. Html) case studies where simulation accuracy dictates security posture.
| Test Scope | Covered Scenario | Missed Failure Mode |
|---|---|---|
| Self-Service API | User-initiated prefix removal | Automated task-runner bulk deletion |
| Data Fidelity | Static prefix lists | Flexible query parameter edge cases |
| Execution Path | Synchronous requests | Asynchronous background service loops |
Competitors like Fastly emphasize programmability, yet their testing rigor remains opaque regarding internal automation bugs. The cost of incomplete coverage is measurable: manual restoration efforts consumed the majority of the incident window. Teams must expand test matrices to include silent, system-initiated workflows alongside user-driven actions. Relying on static mock data creates a false sense of security during automated vs manual configuration transitions.
Recovery actions depend entirely on whether the Addressing API removed only advertisements or also deleted service bindings. Engineers must first validate prefix state to distinguish between simple withdrawal and total configuration loss. Most customers experienced only advertisement removal, allowing restoration by toggling settings in the dashboard. However, a subset suffered binding deletion, requiring manual reconstruction of edge state before traffic could flow.
| Impact State | Required Action | Automation Risk |
|---|---|---|
| Advertisement Only | Toggle dashboard switch | Low |
| Binding Removed | Manual service restore | High |
- Query the Addressing API to verify if service bindings exist for the withdrawn prefix.
- Attempt self-remediation via the dashboard if bindings remain intact.
- Escalate to engineering teams for manual injection if bindings are missing.
Competitors like Google Cloud enforce strict validation steps that prevent instant bulk changes but reduce error velocity. The cost of such safety is slower propagation compared to permissive systems. Organizations weighing these trade-offs often review pricing tiers where lower-cost providers may lack equivalent fail-small controls. Automation should trigger only after binding integrity checks pass; blind re-advertisement fails when dependent objects are missing.
Code Orange Fail Small Initiative Scope and Limits
The Code Orange: Fail Small initiative defines three buckets: controlled rollouts for network changes, removing circular dependencies in break-glass procedures, and reviewing failure modes for traffic systems. Critical work to enhance the Addressing API through staged test mediation remained undeployed during the incident, leaving automated updates vulnerable to unmediated execution. This gap highlights a tension between deployment velocity and safety; while competitors like Google Cloud announce substantial infrastructure updates quarterly, rushing automation without full mediation risks cascading withdrawals.
- Manual restoration efforts consume engineering hours that automated health checks would spare. * Partial recovery states create inconsistent service levels across customer segments. * Missing mock data patterns allow silent logic errors to reach production environments. * Circular dependencies in emergency access procedures delay proven incident response.
Enterprises storing significant corporate data in the cloud face amplified risks when control planes lack strong fail-small mechanisms. Although replacing risky manual actions with safe workflows is the goal, the current limitation is that staged mediation does not yet cover all task-runner execution paths.
All other numbers match exactly.
Restoring BYOIP Services Through Manual Re-advertisement and Configuration Fixes
Defining the Pending Delete Flag and Operational State Separation
Standardizing the `pending_delete` flag prevents empty-value queries from returning full datasets during API calls. This schema change validates input parameters before triggering state mutations, blocking the logic path that withdrew 1,100 prefixes. Separating customer configuration from Production state ensures snapshot deployments occur only after health-mediated checks pass. Operators must configure service bindings by explicitly defining operational states distinct from desired configuration files.
- Define the `pending_delete` boolean strictly to reject null or empty string inputs.
- Implement a circuit breaker that halts snapshot deployment if prefix withdrawal rates spike.
- Verify service bindings exist in the edge cache before executing any advertisement toggle.
The architectural shift reduces reliance on manual restoration, which previously affected hundreds of prefixes. Financial capacity supports these infrastructure changes, with reported cash reserves of substantial millions available for durability projects. However, separating state introduces latency in rollout velocity, creating tension between safety and deployment speed. Enterprises averaging $418,188 annually in plan costs demand immediate propagation, yet mediated processes inherently delay updates. The Flagship feature flag service offers sub-millisecond evaluation to mitigate this lag during controlled rollouts.
At 19:19 UTC, published guidance enabled customers to self-remediate by toggling prefix advertisements within the dashboard interface. Engineers must navigate to the specific BYOIP configuration panel and disable then re-enable the affected range to trigger a fresh BGP announcement. This action forces the Addressing API to push updated state to edge routers, bypassing the stuck withdrawal queue caused by the software.
- Access the Cloudflare dashboard and select the affected account.
- Navigate to Network > Interconnect > BYOIP to view withdrawn ranges.
- Toggle the advertisement switch off, wait thirty seconds, then toggle on.
- Verify route propagation using external looking glass tools.
New circuit breakers now disable snapshot deployments when withdrawal rates spike, arresting broad BGP path changes before they reach edge routers. This mechanism monitors the Addressing API for rapid state mutations, tripping a fail-safe if prefix removal exceeds set thresholds within short windows. Operators must configure these triggers to distinguish between planned maintenance and erroneous bulk deletions.
- Define a maximum withdrawal velocity limit per minute for any single autonomous system.
- Configure the monitoring agent to halt snapshot deployment processes immediately upon threshold breach.
- Require manual approval for any bulk re-advertisement request exceeding ten prefixes.
| Trigger Condition | Action Taken | Recovery Method |
|---|---|---|
| Velocity > 50 prefixes/min | Halt API propagation | Manual review required |
| Broad scope (>a significant share total) | Freeze configuration state | Executive sign-off needed |
| Unexpected null values | Reject transaction | Schema validation fix |
The constraint lies in balancing speed with safety; aggressive thresholds might delay legitimate emergency withdrawals during actual attacks. Large organizations with complex contracts often face higher baseline volatility, requiring tuned parameters rather than static limits found in standard enterprise firewall deployments. Competitors like Zscaler offer similar zero-trust capabilities but rely on different propagation models. InterLIR recommends validating these logic gates against historical traffic patterns to avoid false positives that stall production fixes.
About
Vladislava Shadrina serves as a Customer Account Manager at InterLIR, where she specializes in client relations within the complex domain of IP resources. Her daily work involves guiding customers through the nuances of acquiring and managing IPv4 addresses, making her uniquely qualified to analyze the recent Cloudflare BYOIP outage. Because InterLIR focuses heavily on security, clean BGP, and proper Route Objects, Vladislava understands the critical importance of stable prefix management for network availability. This incident directly impacts the core assets her clients rely on, highlighting the risks associated with changing how BYOIP prefixes are onboarded. Her experience bridging technical network requirements with customer needs allows her to explain why unintentional route withdrawals occur and how proper resource handling prevents such disruptions. Through her role at InterLIR, a leading IPv4 marketplace, she ensures organizations maintain resilient connectivity by emphasizing the value of verified, well-managed IP infrastructure.
Conclusion
Scaling BYOIP architectures reveals a critical breaking point: manual recovery protocols cannot sustain availability when automation defects trigger mass prefix withdrawals. The operational cost of a six-hour outage extends far beyond immediate revenue loss; it erodes trust in the underlying routing fabric and forces engineering teams into reactive fire-fighting modes that delay strategic innovation. Relying on human intervention to restore hundreds of prefixes contradicts the fundamental promise of cloud-native durability. Organizations must transition from reactive circuit breakers to predictive state validation before the next fiscal quarter begins.
Deploy a pre-commit validation script for your BGP automation pipeline by this Friday. This tool must simulate bulk withdrawal scenarios against a staging environment to verify that your velocity thresholds correctly distinguish between malicious activity and legitimate configuration updates. Do not wait for a production incident to test these logic gates. Specifically, configure your system to reject any transaction attempting to withdraw more than ten prefixes without a secondary, time-delayed approval workflow. This immediate step creates a necessary friction layer that prevents single-point defects from cascading into network-wide blackouts. Future stability depends on enforcing these constraints now, rather than hoping manual overrides will suffice during a crisis.
Frequently Asked Questions
Approximately 25% of advertised BYOIP prefixes vanished from the network during the outage. This significant loss triggered BGP path hunting mechanics that prevented end-user connections from reaching their intended destinations successfully.
End users experienced BGP path hunting where traffic traversed networks searching for unreachable destinations. This loop-until-failure scenario persisted until connections timed out, affecting products relying on BYOIP for internet advertisement.
Automated re-advertisement attempts failed for roughly 300 prefixes due to a software bug removing configurations. Engineers had to manually restore these specific routes after dashboard self-remediation proved ineffective for those cases.
The disruption lasted 6 hours and 7 minutes while engineers worked to manually restore configurations. Most of this time was spent returning prefix configurations to their state prior to the initial automated change.
The incident occurred on a network handling 55 million HTTP requests per second globally. This massive volume illustrates how small configuration errors in the addressing API can scale rapidly into widespread service blackouts.
